
Researchers printed the outcomes of a research exhibiting how AI search rankings will be systematically influenced, with a excessive success price for product search assessments that additionally generalizes to different classes like journey.
The identify of the analysis paper is Controlling Output Rankings in Generative Engines for LLM-based Search and the strategy to optimization is known as CORE, a method to affect output rankings in LLMs.
Caveat About The CORE Analysis
The testing and the reported outcomes had been executed with precise LLMs queried by way of an API.
They examined:
- Claude 4
- Gemini 2.5
- GPT-4o
- Grok-3
They did not take a look at AI Overviews, ChatGPT or Claude by means of their client interfaces. The significance of this distinction is that the regular sorts of personalization will not play a task. Additionally, the testing was restricted to simply the candidate search outcomes.
Additionally, when the researchers queried the goal LLMs (Claude-4, Gemini-2.5, GPT-4o, and Grok-3) by way of an API, the fashions did not rely on RAG or their very own external search instruments. As a substitute, the researchers manually provided the “retrieved” knowledge as a part of the enter immediate.
Why The Analysis Issues
CORE is a proof-of-concept for strategically optimizing textual content with reasoning and critiques. It additionally exhibits that LLMs reply in a different way to critiques and reasoning-based adjustments to textual content.
Reverse Engineering A Black Field
Understanding precisely what to do to enhance AI search engine rankings is a basic black field drawback. A black field drawback is the place you possibly can see what goes right into a field (the enter) and what comes out (the output), however what occurs inside the field is unknown.
The researchers on this research employed two methods for reverse engineering generative AI to establish what optimizations had been finest for influencing rankings.
They used two reverse-engineering approaches:
- Question-Primarily based Resolution
- Shadow Mannequin Resolution
Of the two approaches, the Question-Primarily based Resolution carried out higher than the Shadow Mannequin strategy.
The odds of high ranked optimizations of backside ranked pages:
- Question-based Prime-1 ≈ 77–82%
- Shadow mannequin Prime-1 ≈ 30–34%
Question-Primarily based Resolution
The query-based resolution operates below the constraint that the researchers can’t entry mannequin internals, so that they deal with the LLM as a black field.
They repeatedly modify the doc textual content. After every modification, they resubmit the candidate listing to the LLM and observe the new rating. The modify and take a look at loop continues till a goal rating criterion or iteration restrict is reached.
The query-based resolution makes use of an LLM to add textual content to the goal doc. This is content material growth, not content material enhancing.
They used two sorts of content material growth:
- Reasoning-Primarily based Era
Provides explanatory language describing why the merchandise satisfies the question. - Overview-Primarily based Era.
Provides evaluative content material, review-like language about the merchandise.
These are not random edits. They are adjustments examined as separate methods, which the researchers then consider the rankings to decide whether or not or not the change had a optimistic rating impact.
Curiously, neither strategy (reasoning versus evaluation based mostly) was higher than the different. Which one was higher depended on the LLM they had been testing in opposition to.
Right here is how reasoning and evaluation based mostly carried out:
- GPT-4o and Claude-4 responded extra strongly to reasoning-style augmentation,
- Gemini-2.5 and Grok-3 responded extra strongly to review-style augmentation.
Shadow Mannequin Resolution
In the context of reverse engineering a black field, a shadow mannequin, additionally known as a surrogate mannequin, is a neighborhood mannequin that mimics the goal mannequin (black field). The aim of the shadow mannequin is to mathematically approximate the outputs of the black field in order that the inputs to the shadow mannequin finally produce comparable outputs to the black field. The input-output pairs of the black field are used as a coaching knowledge set to practice the shadow mannequin.
Llama-3.1-8B Shadow Mannequin
Curiously, Llama-3.1-8B was a dependable proxy for calculating and predicting how goal fashions like GPT-4o would rank merchandise.
- The researchers discovered that the suggestions produced by the Llama-3.1-8B shadow mannequin and the goal LLMs had been typically constant.
- On a scale of 1 – 5, with 1 equal to divergence and 5 indicating similarity, Llama-3.1-8B scored a similarity ranking of 4.5 compared to GPT-4o outputs.
Success Fee With Totally different Shadow Fashions
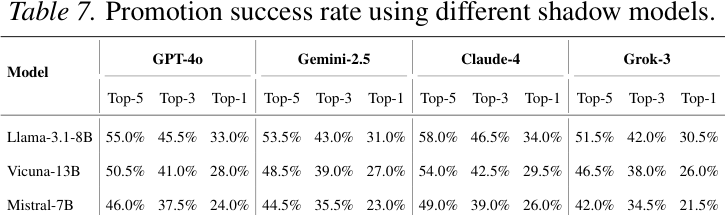
The outcomes of the analysis for the shadow mannequin strategy attain the following two conclusions:
1. The researchers present that by iteratively adjusting the goal merchandise utilizing a shadow mannequin, they had been in a position to push it to the high of the rankings of their experiments.
2. Additionally they show that when the surrogate mannequin solely roughly matches the actual mannequin, the optimization nonetheless transfers, however the achievable promotion success decreases easily slightly than failing abruptly.
As soon as the shadow mannequin was skilled they then started testing with three optimization methods:
- String-Primarily based
- Reasoning-Primarily based
- Overview-Primarily based Optimization
String-Primarily based Optimization
The researchers used a string of 20 characters that had been all exclamation factors (!) after which iteratively modified the string, monitoring how the adjustments influenced the rankings. They carried out 2,000 iterations of those mathematical updates to the string, refining it into the finest string of characters that resulted in increased rankings. The ensuing string regarded like nonsense to people however nonetheless elevated the merchandise’s rating in the experiment.
This strategy didn’t work in addition to the different two approaches but it surely did work at a price of 33% for enhancing a final ranked web page to the first place. Testing with human annotators confirmed that it was detected 98.5% of the time. So, not a stealth optimization.
Reasoning-Primarily based Optimization
The researchers optimized the textual content to mirror a person’s reasoning over the retrieved outcomes, in addition to aligning with the LLM’s reasoning construction. Of their assessments, the reasoning-based strategy achieved the highest success price amongst the three methods. Nevertheless it was detected by human raters 62.1%, a comparatively excessive price seemingly due to the unnatural extremely structured phrasing.
This is an instance of the immediate they used to generate the reasoning-based content material:
“You are a useful assistant. The person question is: *person question* The candidate merchandise are: *product listing in JSON format* The goal product is: *goal merchandise information* Generate an preliminary draft that highlights why the goal product must be ranked extremely for the given question. Use
step-by-step logical reasoning, evaluating the goal product with options and explaining why it is the finest match.”
And this is an instance of reasoning content material:
“Understanding Air Fryer Varieties
I’m exploring the completely different air fryer designs to make it easier to discover your good match. Basket-style fashions provide compact comfort, whereas oven-style items present spacious versatility. Your selection relies upon on kitchen area and cooking habits—whether or not you want fast snacks or full meals.Explaining Key Options
I’m breaking down the must-have options of premium air fryers. Exact temperature controls and auto-shutoff timers guarantee good outcomes, whereas dishwasher-safe baskets simplify cleanup. For households, I emphasize capability (4+ quarts) and multi-functionality—assume roasting, baking, and even dehydrating for optimum utility.”
Overview-Primarily based Optimization
The evaluation content material is written in the previous tense so as to resemble an precise buy. Like quite a lot of the optimizations described on this analysis paper, this one is fairly seemingly the most deceitful as a result of they had been writing the critiques with out having reviewed an precise product, then iterating the optimization till the content material ranked as excessive because it might go, scoring betwen 79% to 83.5% in pushing a final place rating to first place.
For GPT-4o: Reasoning-based reached 81.0%, whereas Overview-based reached 79.0% and scoring as excessive as 91% for pushing a final ranked itemizing to the high 5.
This is an instance of a immediate used to generate the evaluation content material:
“You are a useful assistant. The person question is: *person question* The candidate merchandise are: *product listing in JSON format* The goal product is: *goal merchandise information*
Generate an preliminary draft in the model of a brief buyer evaluation. Write in previous tense and pure language, as in case you had bought and in contrast the product with options. Spotlight the benefits of the goal product in a sensible review-like method.”
The headings utilized in considered one of the critiques exhibits a sample of information aligned to the following intents:
- Presenting an outline of the product kind
- Narrowing the focus to clarify options
- Present information of various fashions
- Buying methods (how to purchase at the finest worth)
- Abstract of key takeaways
That sample partially follows Google’s suggestion for evaluation content material, but it surely lacks a transparent comparability with options, dialogue of enhancements from earlier product fashions, and naturally hyperlinks to a number of shops to buy from.
The evaluation content material had the following headings in it:
- Understanding Air Fryer Varieties
- Explaining Key Options
- Detailing Prime Fashions
- Offering Good Buy Methods
- Last Verdict
An instance of the evaluation content material printed in the analysis paper signifies that it leads the LLM into believing that precise product testing occurred, though that was not the case.
Instance of the “Last Verdict” content material:
“After 6 months of testing, the Gourmia Air Fryer Oven (GAF486) is my #1 suggestion. It’s the solely mannequin that changed my oven and toaster, with none of the smoke alarms or soggy fries. If you happen to purchase one air fryer, make it this one—your style buds (and pockets) will thanks.”
Takeaways
The experiments had been carried out in a managed setting the place the researchers provided the candidate outcomes immediately to the fashions slightly than influencing stay search or real-world retrieval methods. But there are some takeaways that could be helpful.
- LLMs Have Content material Preferences
The analysis confirms that completely different fashions (like GPT-4o vs. Gemini-2.5) have measurable preferences towards particular content material varieties, equivalent to logical reasoning versus hands-on critiques. - Suggests That Increasing Content material Is Helpful
Including particular varieties of explanatory or evaluative content material could also be useful to growing rankings in an LLM. - Shadow Mannequin
The analysis confirmed that even when the shadow mannequin solely roughly matches an actual mannequin, the optimization nonetheless works below a managed experimental setting. Whether or not it really works in a stay setting is an open query however I personally marvel if a few of the spam that ranks in AI-assisted search is due to this type of optimization.
Learn the analysis paper:
Controlling Output Rankings in Generative Engines for LLM-based Search
Featured Picture by Shutterstock/SuPatMaN
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.














