
This put up was sponsored by Peec AI. The opinions expressed on this article are the sponsor’s personal.
Which prompts ought to I prioritize monitoring for AI visibility?
Does precise wording change which manufacturers AI engines suggest?
Do I would like to observe each approach somebody may phrase a immediate in AI search?
Entrepreneurs usually panic about the infinite methods customers may phrase questions to AI engines. However a current examine from Peec AI reveals a way more predictable actuality.
How Immediate Wording Impacts AI Model Visibility
- Variation is restricted, not chaotic: customers phrase issues in a different way. However over 90% of these variations have very comparable which means.
- Wording issues lower than intent: you don’t want to fear about the precise phrases used. Model mentions maintain regular so long as the core intention stays the similar.
- Model issues as a lot as which means: concise key phrases or “record” requests prompted the AI to floor up to 20% extra manufacturers in its solutions in contrast to open-ended prompts.
- Wording Variation Hits Hardest in the Center-of-Funnel: top- and bottom-of-funnel queries are comparatively secure towards phrasing tweaks. Unbranded, industrial middle-of-funnel discovery is much less. As a result of wording variation dictates winners right here, capturing actuality requires absolute phrasing precision and doubtlessly a bigger share of your monitoring quantity.
Two folks can ask an AI the very same industrial query utilizing fully totally different phrases.
One asks for the “greatest noise-cancelling headphones underneath $200.” One other asks, “Which funds over-ear headphones have good noise discount?” The wording modifications. The underlying want largely does not.
This distinction issues for AI model visibility. On the floor, person phrasing seems chaotic. Below the floor, these questions are shut in which means – till they drift simply far sufficient to set off a totally totally different set of manufacturers.
To search out that breaking level, Peec AI analyzed 1,754 prompts, 37,804 AI responses, 5 sectors, and 18 sub verticals throughout ChatGPT, Gemini, Perplexity, Google AI Mode, and Google AI Overviews.
Methodology: How We Examined This
In case your monitoring instrument says you present up for a particular question, does that visibility maintain up when an actual person sorts a variation with the very same intent?
To measure this drop-off, we ran two parallel research.
- Research A: 288 human-written prompts from Rand Fishkin’s followers for 2 totally different intents, leading to 17k+ chats. The authors thank Rand for making the dataset out there to us.
- Research B: 54 base prompts from 18 totally different verticals. For every we generated dozens of variations in tiny cosine-similarity steps, leading to 1k+ whole prompts and 20k+ chats.
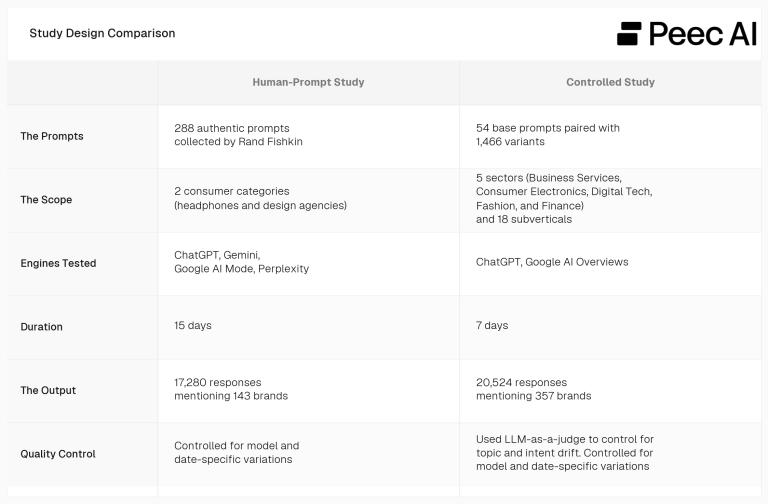
Research A offers us a glimpse into how assorted the prompting type of people is. Research B permits us to observe the influence of tiny modifications in prompts.
In examine A we analyzed the distinction between each pair of prompts (inside every intent). In examine B we analyzed the distinction launched by each small step (inside every trade and intent).
Please notice: we ran each immediate a number of instances to account for the inherent variance of LLM responses.

Why Monitoring Key phrases Misses How Individuals Really Immediate
In AI search, precise key phrase matching solely performs a minor position. “CRM software program” and “customer relationship administration instrument” share virtually no characters however level at the similar objective.
To measure this, we transformed each immediate right into a semantic embedding. We quantified the semantic distance utilizing cosine similarity, which evaluates which means relatively than uncooked textual content size. Making use of this to the human-written prompts yielded a exact similarity worth between 0 and 1.
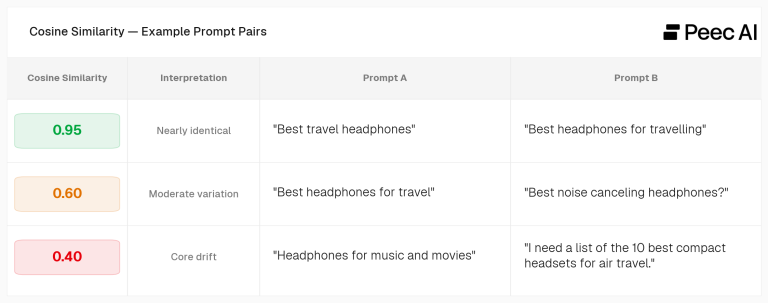
As a substitute of guessing how totally different two prompts are, we are able to quantify the semantic distance.
Perception 1: Human Prompts Solely Look Totally different On The Floor (Principally)
We used two totally different embedding fashions on the 288 human-written prompts (all-MiniLM-L6-v2 and all-mpnet-base-v2). Each confirmed the very same sample: most human prompts clustered tightly with excessive cosine similarity. Individuals use totally different phrases to specific the very same intent. The share of prompts exhibiting giant semantic drift was surprisingly small – accounting for lower than 10% of the variations.
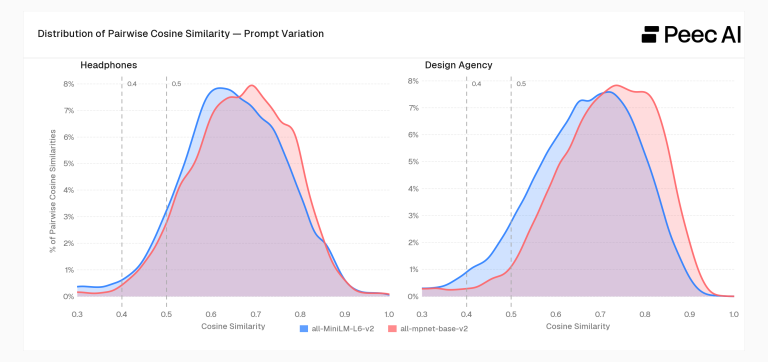
- ~88% to 92% of human immediate pairs sat above a cosine similarity of 0.50.
- ~95% sat above 0.40.
The takeaway: Individuals phrase the similar industrial want in many alternative methods. However mathematically, most of these phrasings find yourself being basically comparable.
Perception 2: Modifications in Wording Solely Impacts Model Mentions Previous a Threshold
In examine A we took all the manufacturers talked about throughout all the runs of the base immediate. We then noticed how the common visibility of all these prompts modifications when altering the immediate in tiny steps.
Towards a near-identical reference group, the common likelihood of a model being talked about throughout our dataset was 4.9%. Nonetheless, when prompts drifted into the lowest similarity bin (0.35 to 0.39), visibility dropped by 2.40 share factors (pp) – a roughly 50% relative lower.
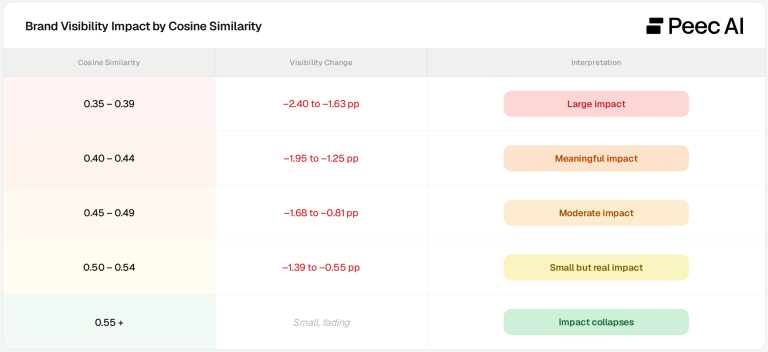
That is a large drop, however discover the place it lives: totally in the left tail.
So long as prompts stayed above 0.50 to 0.60 cosine similarity, relying on the AI Engine, model visibility remained secure. Whereas AI outputs inherently fluctuate, the largest wording-driven visibility losses solely occur when a immediate’s core which means drifts considerably. As a result of most people naturally sort properly above that threshold, immediate monitoring publicity to this threat is narrower than it appears.
The takeaway: Prompts with the similar intent and similar semantic traits largely lead to mentions of the similar manufacturers at the similar frequency.
Beware Of The Semantic Blind Spot!
Excessive similarity doesn’t equal matching intent. “Automotive rental Charleston” and “Automotive rental Charlestown” are 95% comparable however serve totally totally different industrial targets. If a core qualifier modifications, deal with it as a brand new intent. Typical qualifiers are places, merchandise, demographics, and types.
For bigger immediate units, use an LLM-as-a-judge to verify for these shifts routinely.
Perception 3: Immediate Model Influences Model Visibility
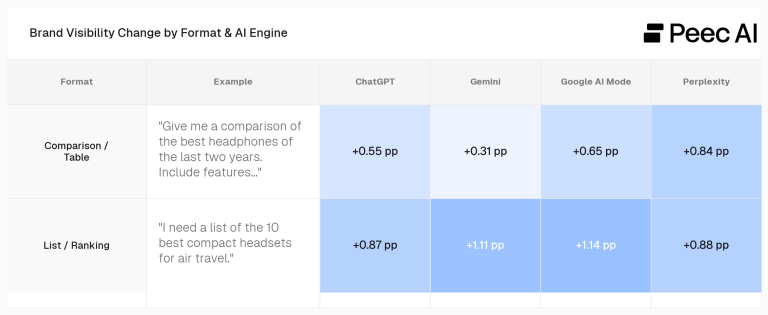
What you immediate is solely half the equation. How you immediate – the type, not simply the intent – modifications what the AI surfaces.
- Format issues. Asking for a comparability, desk, record, or rating persistently surfaces extra manufacturers than open-ended questions. A rating immediate leads to considerably extra model mentions in the reply (+20% common visibility).
- Key phrases beat conversations. Regardless of AI’s conversational interface, concise, keyword-style prompts (e.g., “greatest CRM small enterprise 2026”) lead to extra model mentions (up to +25% common visibility). Key phrase prompts protect a pointy industrial retrieval anchor, whereas persona-engineered prompts (“You are an IT guide…”) usually broaden the question into instructional paths that are much less brand-dense.
- Reply engines react in a different way to constraints. Including funds or function constraints leads to totally different outcomes relying on the mannequin. In ChatGPT and Perplexity, constraints cut back the variety of manufacturers proven. In Gemini and Google AI Overviews, constraints truly elevated the variety of manufacturers. Doubtlessly by triggering further fanout queries.
- Size doesn’t matter. Typing extra filler or conversational phrases has successfully zero influence on which manufacturers are proven in the reply.
The takeaway: Should you combine these types in your immediate monitoring, you must tag them by format.
Perception 4: Center-Of-Funnel Prompts Are The place Wording Really Decides Winners
Immediate wording doesn’t matter equally throughout the purchaser journey (and which prompts you choose to track issues greater than their precise phrasing):
- High-of-funnel (Low Sensitivity): Broad class questions like “What is a CRM?” are extremely secure. Small phrasing variations hardly ever alter which manufacturers seem.
- Center-of-funnel (Excessive Sensitivity): Unbranded industrial queries (“greatest CRMs for a small distant group“) are extremely delicate to small details. We will observe important modifications of talked about manufacturers already in the 0.60 to 0.65 similarity bucket.
- Backside-of-funnel (False Stability): BOFU prompts are usually branded. Their stability in the direction of wording modifications is in all probability a results of all the things being anchored round the model or product identify(s).
The takeaway: To seize the full image you must observe extra variations of your MOFU prompts. For TOFU and BOFU fewer prompts are sufficient. In observe that might imply 25% TOFU, 50% MOFU, and 25% BOFU.
Perception 5: Reply Engines Don’t Behave The Similar Method
Whereas the wording impact’s course is constant throughout all engines, the severity differs:
- Gemini: The impact fades quickest, concentrated in the lowest similarity buckets.
- Google AI Overviews: Present the most persistent middle-of-funnel sensitivity. Small wording modifications influence visibility rather more than in another engine.
- ChatGPT, Perplexity, & Google AI Mode: Visibility penalties span a wider vary of variations. On ChatGPT, middle-of-funnel model loss triggers the second phrasing slips beneath the 0.60 to 0.64 bucket
The takeaway: Deal with fastidiously when aggregating information throughout fashions.
The Takeaway: 6-Step Measurement Playbook
- Section by funnel stage early. High-of-funnel queries present a secure baseline for class consciousness, and bottom-of-funnel prompts monitor branded retrieval environments. Nonetheless, as a result of wording variation actively dictates the winners in the industrial middle-of-funnel, capturing actuality there requires absolute phrasing precision and a bigger share of your monitoring quantity
- Anchor on your purchaser’s precise phrasing. There is no universally “good” base immediate. The suitable anchor matches your goal intent and persona. Do a fast actuality verify: ask a couple of colleagues how they might naturally sort that precise question. If their solutions threat dropping beneath the essential 0.50 similarity threshold, your phrasing is too slim and also you want to observe a further anchor.
- Don’t combine immediate types. Format, archetype, and constraint ranges every shift the baseline – a listing immediate and an open-ended immediate do not share the similar beginning line. Tag your prompts by format so you’ll be able to evaluate apples to apples
- Watch constraint details in the middle-of-funnel. And not using a model anchor, minor constraint shifts – including an integration, group dimension, or funds restrict – can fully change which manufacturers floor. Observe a number of prompts that seize these nuances inside the similar persona.
- Don’t observe the left tail. Human variation clusters naturally, and visibility solely drops sharply when prompts drift into the 0.40 to 0.50 similarity vary. Focus your monitoring funds on the dense semantic center the place most actual patrons truly sort.
- Report every AI engine individually. Get the per-engine image before creating any blended views. That’s the way you inform whether or not a visibility change is a broad market shift or an algorithm quirk in a single system.
What This Research Doesn’t Show
These patterns have been constant throughout 37,804 AI responses. However hold these caveats in thoughts:
- Traits are not assured. These percentages mirror the sturdy patterns we noticed. They are not static guidelines for each question.
- Regulated industries could differ. We examined 18 subverticals. It is attainable that regulated classes like healthcare behave in a different way due to stricter AI security guardrails.
- Engines always change. The precise percentages will shift as fashions evolve or grounding programs change. Solely the core mechanics (wording threshold, middle-of-funnel sensitivity, and magnificence baselines) will stay.
How To Observe AI Prompts With out Chasing Each Variation
Should you are hesitant to observe prompts as a result of “each immediate is distinctive” and “you do not know the way precisely your viewers is typing”, you’ll be able to calm down. The wording house isn’t a flat, chaotic unfold of random variations; it has form and construction.
There is no want to monitor each single phrase or chase an limitless record of variations. You solely want to know the intent and the related contexts you need to monitor. Have a look at the true which means, separate the type, phase by funnel stage, and browse the AI engines one after the other.
Picture Credit
Featured Picture: Picture by Peec AI Used with permission.
In-Submit Pictures: Pictures by Peec AI Used with permission.
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.













