
Increase your expertise with Development Memo’s weekly professional insights. Subscribe for free!
In “The science of how AI pays attention,” I analyzed 1.2 million ChatGPT responses to perceive precisely how AI reads a web page. This is Half 2.
The place Half 1 informed you the place on a web page AI appears to be like, this one tells you which pages AI routinely considers.
The information clarifies:
- Why ~30 domains personal 67% of citations in any matter.
- The web page construction that earns citations throughout 50+ distinct queries vs. the one which will get cited as soon as.
- Whether or not the ski ramp from Half 1 is really steeper or flatter in your vertical.

1. ~30 Domains Personal 67% Of AI Citations Per Subject
Traditional search is a winner-takes-all game. The highest end result will get disproportionately extra clicks than the second. Is that additionally true for ChatGPT solutions? Is the distribution of cited domains democratic or totalitarian?
Strategy:
- Compute the quotation share per area per vertical.
- Calculate the cumulative share captured by the prime 10% of domains.
- Dataset: 21,482 ChatGPT quotation rows, 670 distinctive domains, 2,344 distinctive URLs, 127 distinctive prompts.
Outcomes: The highest 10 domains take 46% of all citations in a subject. The highest 30 take 67%.
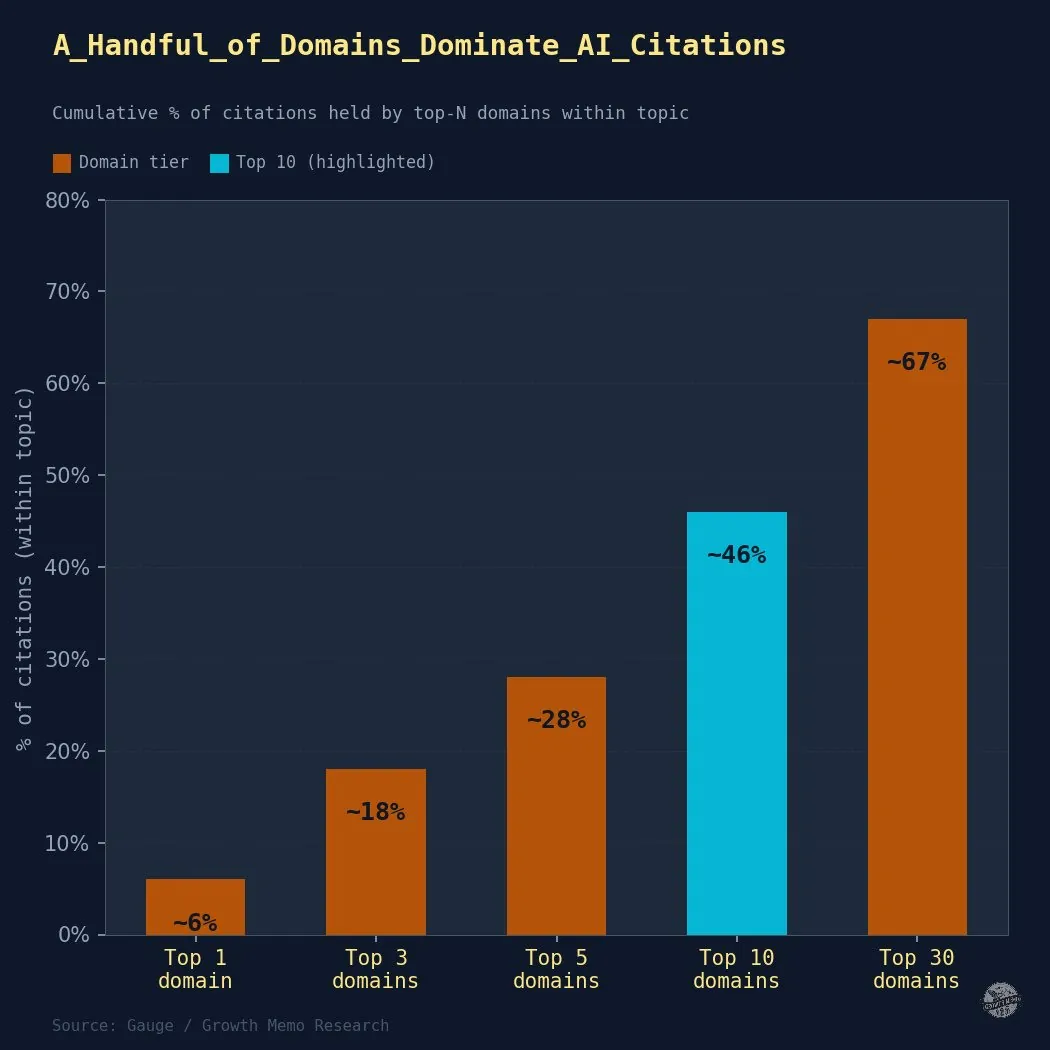
AI quotation is barely much less concentrated than conventional natural search, however nonetheless excessive:
- Successfully, there are ~30 seats (domains) at the quotation desk for any given matter. Every thing else is almost invisible.
- Instance: storylane.io seems as a cited supply throughout 102 distinct prompts (distinctive questions requested of ChatGPT), reprise.com throughout 98. Although reprise.com has extra complete citations (1,369 vs. storylane.io’s 968), storylane.io exhibits up in solutions to a broader vary of various questions.
We confirmed these findings in product-comparison verticals (SaaS instruments, monetary advisors). Nonetheless, you’ll see under that the sample is weaker in healthcare and open internet matters, the place no single area dominates. Notably, the training sector receives the most AI citations of any vertical we studied.
What The Trade Patterns Confirmed
The findings above are from product comparability verticals (SaaS, monetary advisors), however the sample is weaker in healthcare and open internet matters, the place no single area dominates, and stronger in the training sector.
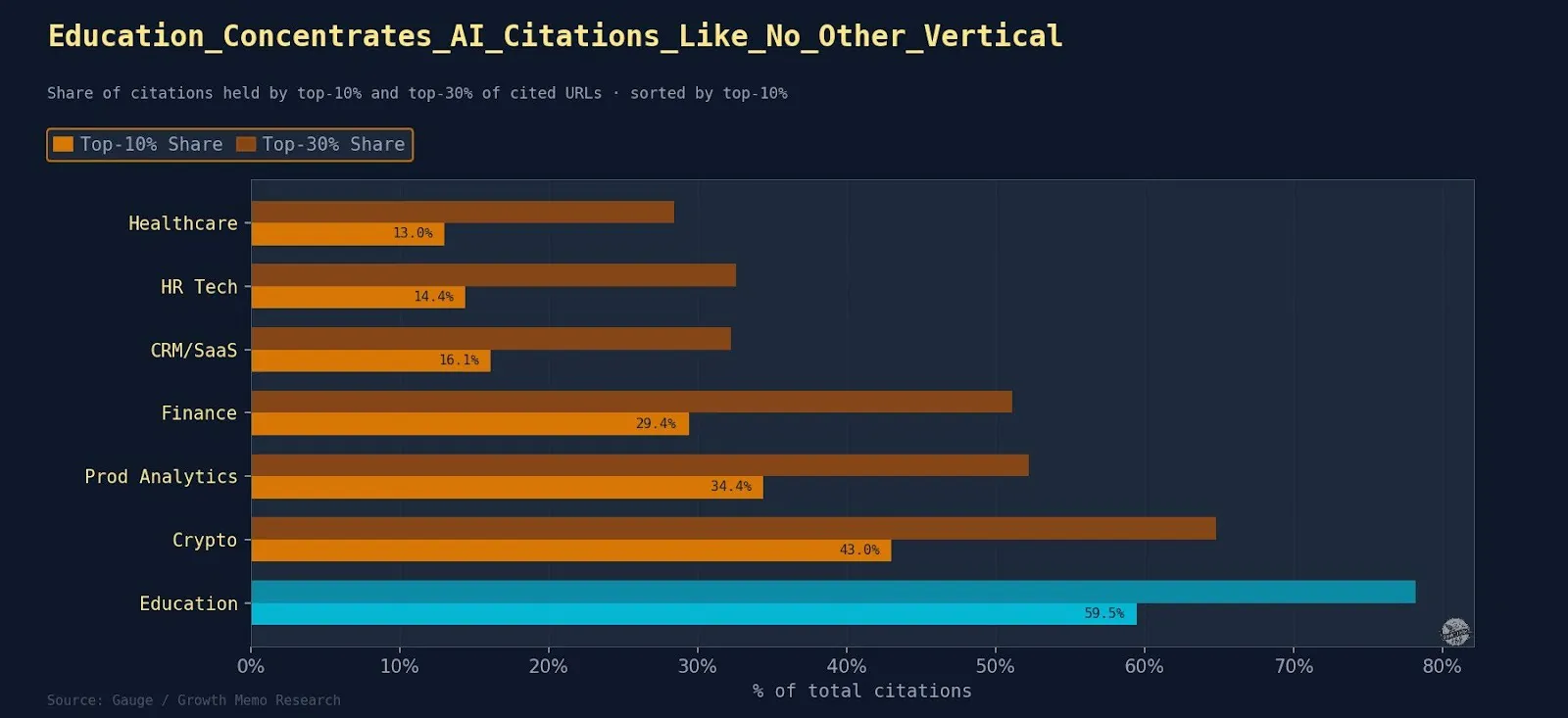
Training is winner-take-most: the prime 10% of domains seize 59.5% of all citations.
- In case you are not already in the prime 5-10 domains in training, reaching quotation breadth is exceptionally hard.
- tefl.org alone solutions 102 distinctive prompts and holds 18.75% of all Training citations.
Crypto is the second most concentrated at 43.0% for the prime 10%.
- A small set of technical documentation and comparability websites (alchemy.com, quicknode.com, chainstack.com) dominate Solana RPC and infrastructure queries.
- The technical nature of Solana queries means few credible sources exist; as soon as a site earns belief on this area of interest, it captures a big share.
Finance sits at 29.4% for top-10%.
- Focus is query-type particular: Monetary advisor locator pages (forfiduciary.com at 139 distinctive prompts, smartasset.com at 168 distinctive prompts) dominate city-level advisor queries.
- However the lengthy tail of monetary product queries retains complete focus average.
Healthcare is the least concentrated at 13.0% for the prime 10%.
- No single area dominates. New entrants have a sensible path to quotation attain.
- The quotation floor is unfold throughout a whole bunch of domains, every protecting a small slice of telehealth, HIPAA compliance, and healthcare app queries.
CRM/SaaS and HR Tech are equally diffuse (16.1% and 14.4% top-10%).
- These are multi-product software program classes the place dozens of comparability websites, evaluate platforms, and vendor pages cut up citations.
- Monday.com leads CRM with solely 2.88% of all citations (37 distinctive prompts). A genuinely open aggressive discipline
Prime Takeaways
1. Breadth of matter protection issues greater than area authority. A single well-structured comparability web page (be taught.g2.com: 65 distinctive prompts, 495 citations) can nonetheless outperform the complete area portfolio of a well known model. The aim is not to rank for one question, however to reply a cluster.
2. Focus displays class maturity. Fragmentation is a chance. Training and Crypto have slender, well-defined question areas the place a number of authoritative sources have locked in belief. Healthcare and CRM are broad, fragmented classes the place no single area dominates. That fragmentation is your opening.
3. Quotation attain (the variety of distinct prompts a site solutions) is a extra helpful strategic metric than uncooked quotation depend. In low-concentration verticals like Healthcare and CRM, a centered 30-50 web page strategy can realistically compete for a seat at the desk. In high-concentration verticals like Training and Crypto, the path is narrower: turn out to be the definitive useful resource on a particular sub-topic or settle for that you just’re combating for scraps.
2. The Quotation Benefit Begins At 10,000 Phrases
In traditional Search, phrase depend and web page size are considerably indicative of ranks, so long as the high quality is excessive. I questioned, once more, if that is additionally true for exhibiting up in ChatGPT solutions?
Strategy
- Measure uncooked textual content size of each cited web page.
- Group size into seven buckets.
- For every bucket, calculate common citations per web page.
Outcomes: Extra phrases do certainly correlate with extra citations, however there’s a ceiling.
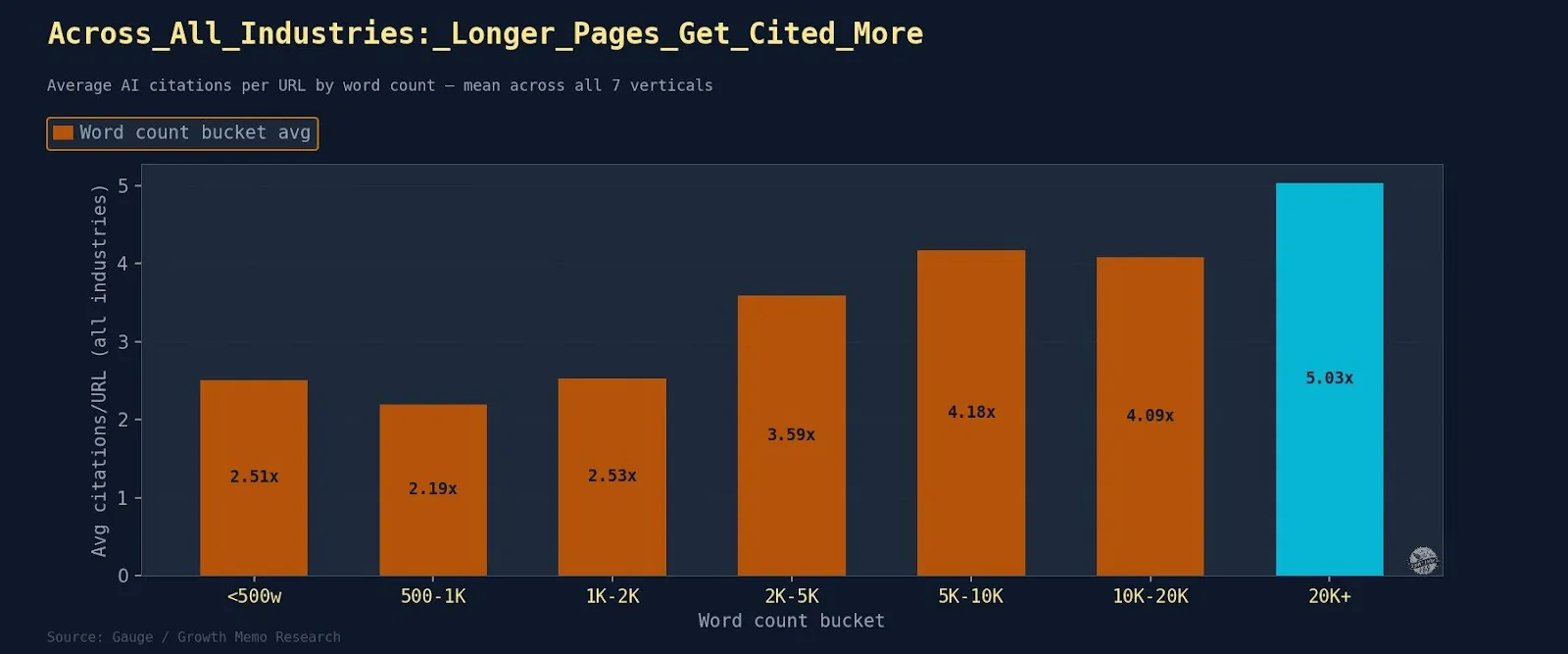
The 5,000-to-10,000 soar is the largest single step – almost 2x. Pages above 20,000 characters common 10.18 citations every vs. 2.39 for pages beneath 500 characters.
The size impact is vertical-specific: Finance inverts it solely. Excessive-cited Finance pages common 1,783 phrases vs. 2,084 for low-cited pages – a 0.86x raise. Authoritative compact sources, fee tables, and regulatory summaries outperform complete guides there. The ten,000-character rule holds for SaaS and editorial content material.
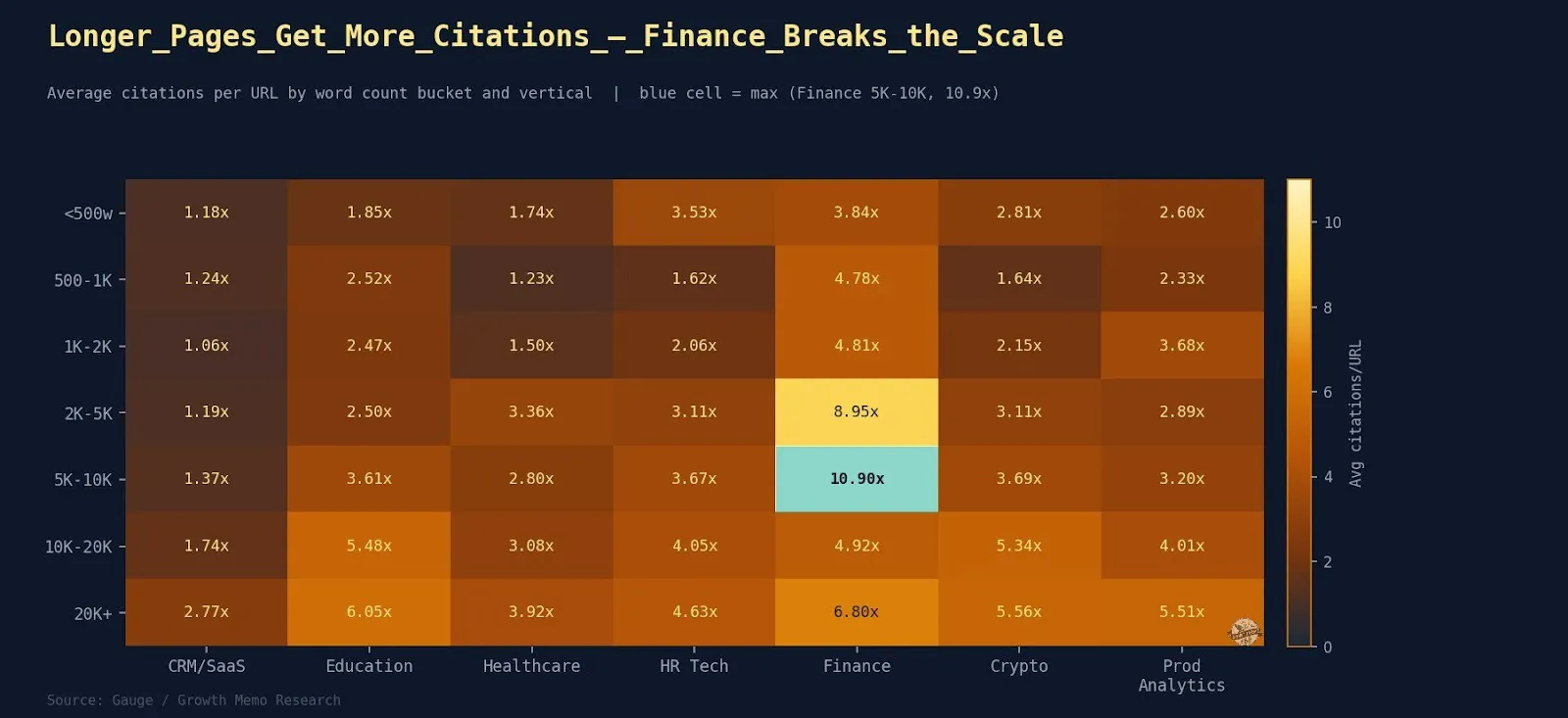
Finance peaks at 5,000-10,000 phrases (10.9 citations/web page), then drops sharply at 10,000-20,000 (4.92 citations/web page).
- Finance additionally exhibits the steepest absolute acquire: Pages beneath 500 phrases earn solely 3.84 citations/web page whereas 5,000-10,000 pages earn 10.9, which is a 2.8x multiplier from size optimization alone.
- Very lengthy Finance pages could dilute the citation-triggering content material with redundant element.
Training exhibits the clearest length-wins-everything sample.
- Citations per web page climb steadily from 1.85 (beneath 500 phrases) to 6.05 (20K+ phrases) with no drop-off.
Crypto and Product Analytics behave equally to Training.
- Size constantly pays off, plateauing round the 10,000-20,000 tier (5.34 and 4.01, respectively). Each are technical verticals the place comprehensiveness indicators authority.
SaaS exhibits the weakest size impact: Citations per web page vary from 1.06 (1,000-2,000 phrases) to 2.77 (20,000+ phrases).
- Even the longest CRM pages solely get 2.77 citations per web page on common.
- On this vertical, size alone does not decide citations. Format, construction, and area authority seem extra vital.
Healthcare exhibits a average size impact (1.74 to 3.92 citations/web page).
- However with one anomaly: 5,000-10,000 phrases (2.80) underperforms vs. 2,000-5,000 phrases (3.36).
- Very lengthy Healthcare pages could embrace an excessive amount of scientific element that dilutes citation-triggering content material.
Prime Takeaways
1. Common discovering: Very quick pages (beneath 1,000 phrases) underperform in each vertical. The underperformance of skinny content material is constant, however the reward for lengthy content material is vertical-specific.
2. Goal your size primarily based on business, content material sort, and question intent, not a common phrase depend. For Finance verticals: Intention for five,000-10,000 phrases. Training, Crypto, and Product Analytics: Go so long as attainable. CRM/SaaS: Prioritize construction over phrase depend.
3. 58% Of Cited URLs Are Cited As soon as
After we take a look at the citations inside a subject, we frequently see many pages on a site getting cited. So, what number of citations can a single web page get?
Strategy
1. Rely the variety of distinctive prompts for every web page.
- Classify variety of citations into: 1, 2-5, 6-10, 11+.
- Examine the prime URLs per vertical for structural patterns.
Outcomes: On common, 67% of cited URLs seem in just one immediate.
Consider it like a footprint recreation. Uncooked quotation depend tells you the way common a web page is. Quotation breadth tells you the way strategically priceless it is. An evergreen web page in AI quotation is not one which will get cited loads; it is one which retains showing throughout numerous queries.
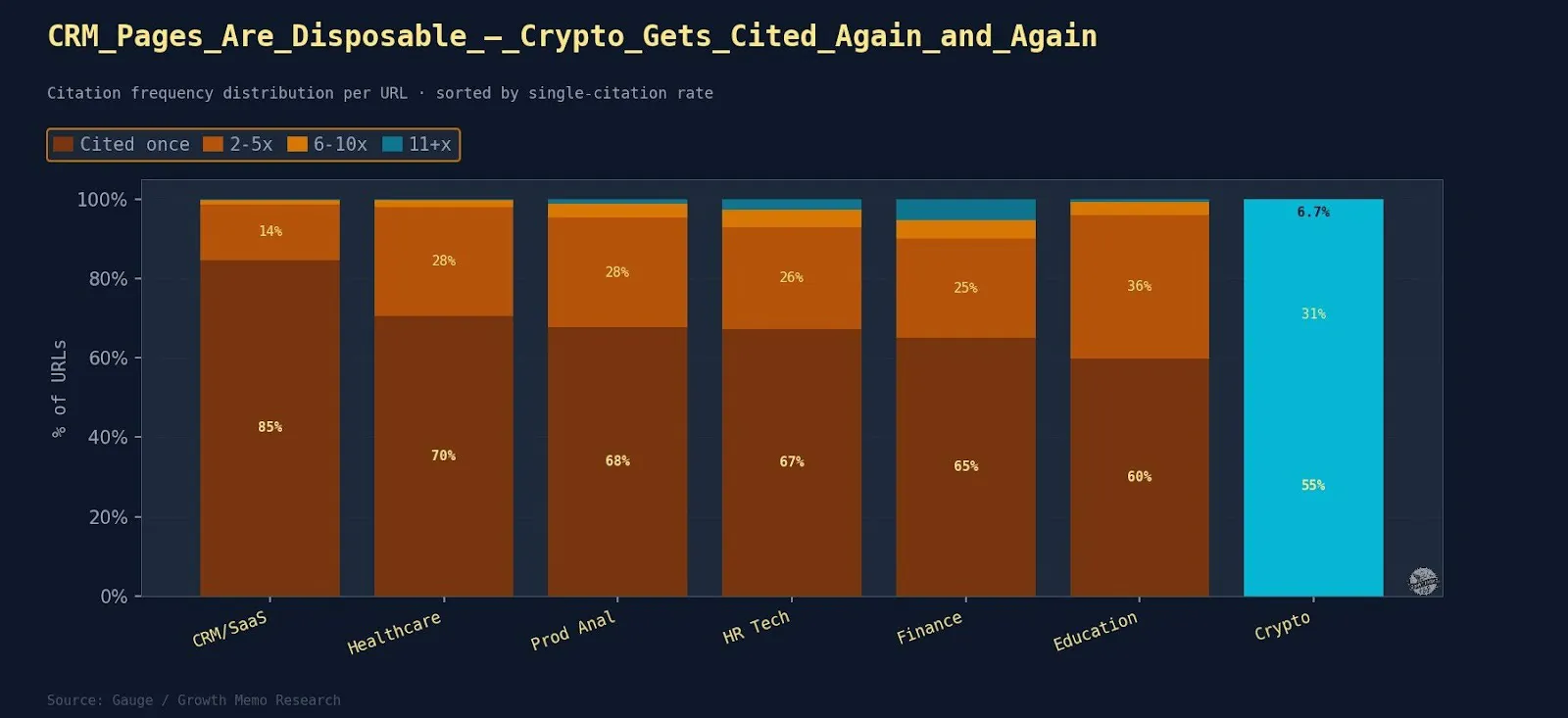
The highest 4.8% of URLs (cited 10+) are all category-level comparisons or guides answering “what is it,” “who makes use of it,” “how to select,” and “pricing” in a single URL.
The quotation pool isn’t a meritocracy of the finest reply, however the diploma varies sharply.
- CRM/SaaS has the highest one-hit fee at 84.7%.
- Finance produces the highest-reach evergreen pages: forfiduciary.com covers 119 distinctive prompts.
- Crypto generates the most concentrated evergreen pages at 55.4% in the technical tier: chainstack.com/best-solana-rpc-providers-in-2026 (63 prompts), alchemy.com/overviews/solana-rpc (62 prompts), and rpcfast.com/weblog/rpc-node-providers (61 prompts). All three are comparability pages protecting the Solana RPC supplier panorama from barely completely different angles.
- Training evergreen pages observe a unique logic: tefl.org, internationalteflacademy.com, and gooverseas.com get cited broadly as a result of they reply TEFL-adjacent queries (price, location, certification sort) from a single useful resource. One URL serves many question angles.
1. Evergreen pages share constant structural patterns: Class-level information format (finest X for 2025/2026), broad matter protection inside a single web page (what is X, how to select X, prime X distributors, pricing), and specific yr anchoring in URL or title. Pages that reply a category of questions earn quotation breadth.
2. The highest 5 evergreen pages in each vertical are both comparability roundups, authoritative guides, or listing/itemizing pages. No skinny single-topic web page reaches the 11+ immediate tier in any vertical.
3. A single evergreen web page protecting 10+ question intents is value extra in AI quotation attain than 10 single-intent pages. The ROI of complete content material is front-loaded: one well-built web page compounds quotation attain over time. The lengthy tail exists, however the prime 5% of pages seize a disproportionate share of ongoing quotation exercise.
4. The Ski Ramp Is Steeper In Some Verticals
The science of how AI pays attention confirmed that ChatGPT cites 44.2% from the prime 30% of any web page. Does that pattern maintain throughout completely different verticals?
Strategy: Re-run the similar positional evaluation throughout 7 verticals with 42,460 matched citations.
Outcomes: The pattern is actual however varies by matter. One quantity holds in all places: The underside 10% of any web page earns 2.4-4.4% of citations, roughly 1 / 4 of what the peak band earns. The conclusion part is almost invisible to AI, no matter vertical.
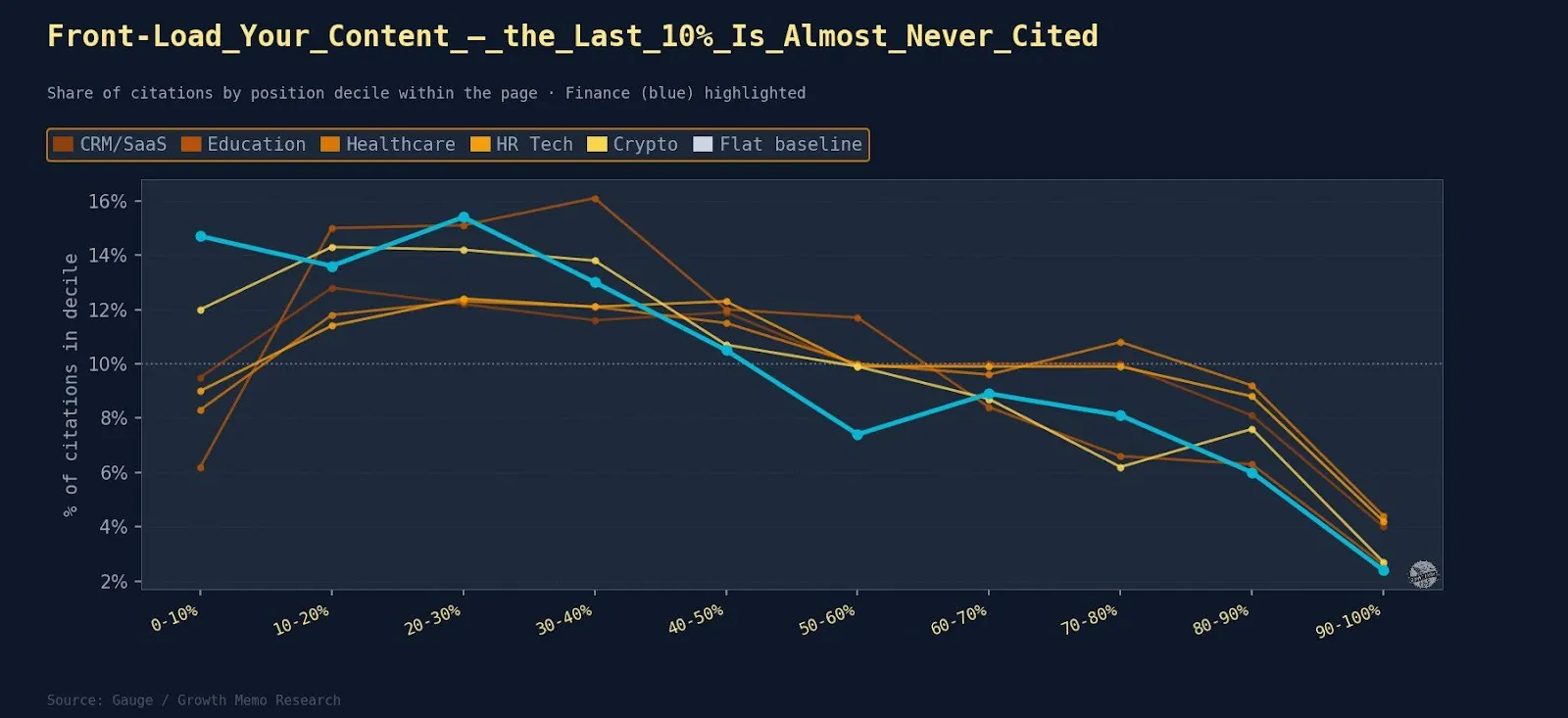
What The Trade Patterns Confirmed
The true peak decile throughout all verticals is not the very opening. The ten-20% band is the place AI reads hardest in each vertical. The primary 10% is usually navigation, headlines, and intro fluff that AI skips.
- Finance is the excessive case. 43.7% of citations land in the first 30% of the web page. Finance pages front-load fee information, percentages, and key figures. AI grabs them and infrequently reads previous the midway level.
- Healthcare and HR Tech have the flattest ramps. Helpful content material is distributed extra evenly throughout these pages.
- Training peaks at the 30-40% decile somewhat than 10-20%, as a result of academic content material tends to bury the key reply barely deeper after the intro.
Prime Takeaways
1. Put your most citable claims and information in the first 30% of the web page – it doesn’t matter what business you’re in. Summaries and conclusions hardly ever get cited.
2. For Finance manufacturers: Entrance-load your thesis and statistics as a lot as attainable.
What This Means For How You Construct LLM Visibility
The domains that personal quotation share didn’t get there by writing higher sentences. They constructed pages that maintain true topical authority, addressing a number of queries in a single place, after which repeated that authority throughout sufficient sub-topics to maintain a number of seats at the desk.
Getting cited throughout 30, 60, or 100 distinct prompts requires a targeted content architecture: pages constructed round question clusters and proudly owning complete matters somewhat than particular person key phrases. Groups that maintain the conventional “one key phrase, one web page” mannequin will probably be structurally locked out of AI quotation, even when their particular person pages are superbly written.
However as the information exhibits, there is no common playbook. The techniques that work for a broad CRM platform might actively hurt a Finance model.
Methodology
We analyzed ~98,000 ChatGPT quotation rows pulled from roughly 1.2 million ChatGPT responses from Gauge.
As a result of AI behaves in another way relying on the matter, we remoted the information throughout 7 distinct, verified verticals to guarantee the findings weren’t skewed by one particular business.
Analyzed verticals:
- B2B SaaS
- Finance
- Healthcare
- Training
- Crypto
- HR Tech
- Product Analytics
To reverse-engineer the quotation choice, I ran the information by means of a number of layers of study:
- Structural parsing: I measured the uncooked character size of each cited web page and mapped heading hierarchies (H1s, H2s, H3s) to see how information structure impacts visibility.
- Positional mapping: I used Jaccard sliding-window similarity to pinpoint precisely the place on the web page the AI extracted its solutions from, down to the particular decile.
- Entity & Sentiment extraction: I ran the opening textual content of distinctive cited URLs by means of the Google Pure Language API to classify named entities (dates, costs, merchandise) and used TextBlob to rating sentiment, evaluating the efficiency of company content material towards user-generated content material (UGC).
Featured Picture: Roman Samborskyi/Shutterstock; Paulo Bobita/Search Engine Journal
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.












