
After we’re speaking about grounding, we imply fact-checking the hallucinations of planet destroying robots and tech bros.
In order for you a non-stupid opening line, when fashions settle for they don’t know one thing, they floor leads to an try to reality test themselves.
Comfortable now?
TL;DR
- LLMs don’t search or retailer sources or particular person URLs; they generate solutions from pre-supplied content material.
- RAG anchors LLMs in particular data backed by factual, authoritative, and present information. It reduces hallucinations.
- Retraining a basis mannequin or fine-tuning it is computationally costly and resource-intensive. Grounding outcomes is far cheaper.
- With RAG, enterprises can use inside, authoritative information sources and acquire comparable mannequin efficiency will increase with out retraining. It solves the lack of up-to-date data LLMs have (or slightly don’t).
What Is RAG?
RAG (Retrieval Augmented Technology) is a type of grounding and a foundational step in reply engine accuracy. LLMs are educated on huge corpuses of information, and each dataset has limitations. Notably when it comes to issues like newsy queries or altering intent.
When a mannequin is requested a query, it doesn’t have the acceptable confidence rating to reply precisely; it reaches out to particular trusted sources to floor the response. Quite than relying solely on outputs from its training data.
By bringing on this related, external information, the retrieval system identifies related, comparable pages/passages and consists of the chunks as a part of the reply.
This gives a very invaluable have a look at why being in the coaching information is so essential. You are extra seemingly to be chosen as a trusted supply for RAG should you seem in the coaching information for related matters.
It’s one in every of the explanation why disambiguation and accuracy are extra essential than ever in in the present day’s iteration of the web.
Why Do We Want It?
As a result of LLMs are notoriously hallucinatory. They’ve been educated to offer you a solution. Even when the reply is fallacious.
Grounding outcomes gives some reduction from the circulate of batshit information.
All fashions have a cutoff restrict of their coaching information. They can be a year old or more. So something that has occurred in the final yr can be unanswerable with out the real-time grounding of info and information.
As soon as a mannequin has ingested a sizeable quantity of coaching information, it is far cheaper to rely on a RAG pipeline to reply new information slightly than re-training the mannequin.
Dawn Anderson has an incredible presentation known as “You Can’t Generate What You Can’t Retrieve.” Properly value a learn, even should you can’t be in the room.
Do Grounding And RAG Differ?
Sure. RAG is a type of grounding.
Grounding is a broad brush time period utilized used to apply to any sort of anchoring AI responses in trusted, factual information. RAG achieves grounding by retrieving related paperwork or passages from external sources.
In virtually each case you or I’ll work with, that supply is a reside internet search.
Consider it like this;
- Grounding is the ultimate output – “Please cease making issues up.”
- RAG is the mechanism. When it doesn’t have the acceptable confidence to reply a question, ChatGPT’s inside monologue says, “Don’t simply lie about it, verify the information.“
- So grounding may be achieved by fine-tuning, immediate engineering, or RAG.
- RAG both helps its claims when the threshold isn’t met or finds the supply for a narrative that doesn’t seem in its coaching information.
Think about a reality you hear down the pub. Somebody tells you that the scar they’ve on their chest was from a shark assault. A hell of a narrative. A fast little bit of verifying would inform you that they choked on a peanut in mentioned pub and had to have a nine-hour operation to get part of their lung eliminated.
True story – and one I believed till I used to be at college. It was my dad.
There is a variety of conflicting information on the market as to what internet search these fashions use. Nevertheless, now we have very strong information that ChatGPT is (still) scraping Google’s search results to type its responses when utilizing internet search.
Why Can No-One Remedy AI’s Hallucinatory Downside?
Lots of hallucinations make sense whenever you body it as a mannequin filling the gaps. The fails seamlessly.
It is a believable falsehood.
It’s like Elizabeth Holmes of Theranos infamy. You recognize it’s fallacious, however you don’t need to imagine it. The you right here being some immoral previous media mogul or some funding agency who cheaped out on the due diligence.
“At the same time as language fashions develop into extra succesful, one problem stays stubbornly exhausting to absolutely clear up: hallucinations. By this we imply situations the place a mannequin confidently generates a solution that isn’t true.”
That is a direct quote from OpenAI. The hallucinatory horse’s mouth.
Fashions hallucinate for a number of causes. As argued in OpenAI’s most up-to-date analysis paper, they hallucinate as a result of coaching processes and analysis reward a solution. Proper or not.

In case you consider it in a Pavlovian conditioning sense, the mannequin will get a deal with when it solutions. However that doesn’t actually reply why fashions get issues fallacious. Simply that the fashions have been educated to reply your ramblings confidently and with out recourse.
This is largely due to how the mannequin has been educated.
Ingest sufficient structured or semi-structured data (with no proper or fallacious labelling), they usually develop into extremely proficient at predicting the subsequent phrase. At sounding like a sentient being.
Not one you’d hang around with at a celebration. However a sentient sounding one.
If a reality is talked about dozens or tons of of occasions in the coaching information, fashions are far less-likely to get this fallacious. Fashions worth repetition. However seldom referenced info act as a proxy for what number of “novel” outcomes you would possibly encounter in additional sampling.
Info referenced this sometimes are grouped underneath the time period the singleton rate. In a never-before-made comparability, a excessive singleton charge is a recipe for catastrophe for LLM coaching information, however sensible for Essex hen events.
In accordance to this paper on why language models hallucinate:
“Even when the coaching information have been error-free, the targets optimized throughout language mannequin coaching would lead to errors being generated.”
Even when the coaching information is 100% error-free, the mannequin will generate errors. They are constructed by folks. Individuals are flawed, and we love confidence.
A number of post-training strategies – like reinforcement studying from human suggestions or, on this case, types of grounding – do cut back hallucinations.
How Does RAG Work?
Technically, you could possibly say that the RAG course of is initiated lengthy before a question is obtained. However I’m being a bit arsey there. And I’m not an professional.
Normal LLMs supply information from their databases. This information is ingested to prepare the mannequin in the type of parametric memory (extra on that later). So, whoever is coaching the mannequin is making specific choices about the sort of content material that can seemingly require a type of grounding.
RAG provides an information retrieval part to the AI layer. The system:
➡️ Retrieves information
➡️ Augments the immediate
➡️ Generates an improved response.
A extra detailed clarification (do you have to need it) would look one thing like:
- The person inputs a question, and it’s transformed into a vector.
- The LLM makes use of its parametric reminiscence to try to predict the subsequent seemingly sequence of tokens.
- The vector distance between the question and a set of paperwork is calculated utilizing Cosine Similarity or Euclidean Distance.
- This determines whether or not the mannequin’s saved (or parametric) reminiscence is able to fulfilling the person’s question with out calling an external database.
- If a sure confidence threshold isn’t met, RAG (or a type of grounding) is known as.
- A retrieval question is despatched to the external database.
- The RAG structure augments the current reply. It clarifies factual accuracy or provides information to the incumbent response.
- A ultimate, improved output is generated.
If a mannequin is utilizing an external database like Google or Bing (which all of them do), it doesn’t want to create one to be used for RAG.
This makes issues a ton cheaper.
The issue the tech heads have is that all of them hate one another. So when Google dropped the num=100 parameter in September 2025, ChatGPT citations fell off a cliff. They might not use their third-party companions to scrape this information.
It’s value noting that extra trendy RAG architectures apply a hybrid mannequin of retrieval, the place semantic looking out is run alongside extra fundamental keyword-type matches. Like updates to BERT (DaBERTa) and RankBrain, this implies the reply takes the total doc and contextual which means into consideration when answering.
Hybridization makes for a far superior mannequin. In this agriculture case study, a base mannequin hit 75% accuracy, fine-tuning bumped it to 81%, and fine-tuning + RAG jumped to 86%.
Parametric Vs. Non-Parametric Reminiscence
A mannequin’s parametric reminiscence is primarily the patterns it has discovered from the coaching information it has greedily ingested.
Throughout the pre-training section, the fashions ingest an infinite quantity of information – phrases, numbers, multi-modal content material, and so forth. As soon as this information has been become a vector space model, the LLM is in a position to determine patterns in its neural network.
While you ask it a query, it calculates the likelihood of the subsequent doable token and calculates the doable sequences by order of likelihood. The temperature setting is what gives a degree of randomness.
Non-parametric reminiscence shops (or accesses) information in an external database. Any search index being an apparent one. Wikipedia, Reddit, and so forth., too. Any sort of ideally well-structured database. This permits the mannequin to retrieve particular information when required.
RAG methodologies are in a position to experience these two competing, extremely complementary disciplines.
- Fashions acquire an “understanding” of language and nuance by parametric reminiscence.
- Responses are then enriched and/or grounded to verify and validate the output through non-parametric reminiscence.
Greater temperatures improve randomness. Or “creativity.” Decrease temperatures the reverse.
Satirically these fashions are extremely uncreative. It’s a foul manner of framing it, however mapping phrases and paperwork into tokens is about as statistical as you may get.
Why Does It Matter For search engine marketing?
In case you care about AI search and it issues for what you are promoting, you want to rank effectively in search engines like google and yahoo. You need to pressure your manner into consideration when RAG searches apply.
You need to know the way RAG works and the way to affect it.
In case your model options poorly in the coaching information of the mannequin, you can’t instantly change that. Properly, for future iterations, you possibly can. However the mannequin’s data base isn’t up to date on the fly.
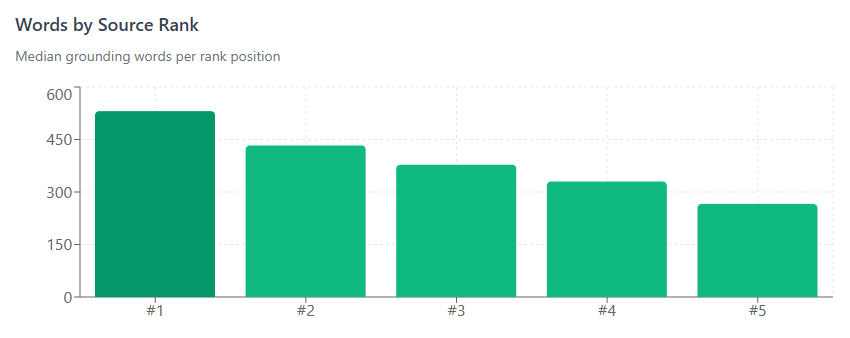
So, you rely on that includes prominently in these external databases so as to be a part of the reply. The higher you rank, the extra seemingly you are to function in RAG-specific searches.
I extremely advocate watching Mark Williams-Cook dinner’s From Rags to Riches presentation. It’s glorious. Very cheap and provides some clear steerage on how to discover queries that require RAG and how one can affect them.
Principally, Once more, You Want To Do Good search engine marketing
- Be sure you rank as excessive as doable for the related time period in search engines like google and yahoo.
- Be sure you perceive how to maximize your likelihood of that includes in an LLM’s grounded response.
- Over time, do some higher advertising and marketing to get your self into the coaching information.
All issues being equal, concisely answered queries that clearly match related entities that add one thing to the corpus will work. In case you actually need to comply with chunking best practice for AI retrieval, someplace round 200-500 characters appears to be the candy spot.
Smaller chunks permit for extra correct, concise retrieval. Bigger chunks have extra context, however can create a extra “lossy” setting, the place the mannequin loses its thoughts in the center.
Prime Suggestions (Similar Outdated)
I discover myself repeating these at the finish of each coaching information article, however I do suppose all of it stays broadly the similar.
- Reply the related question excessive up the web page (front-loaded information).
- Clearly and concisely match your entities.
- Present some degree of information acquire.
- Keep away from ambiguity, particularly in the middle of the document.
- Have a clearly outlined argument and web page construction, with well-structured headers.
- Use lists and tables. Not as a result of they’re much less resource-intensive token-wise, however as a result of they have an inclination to comprise much less information.
- My god be attention-grabbing. Use distinctive information, photos, video. Something that can fulfill a person.
- Match their intent.
As at all times, very search engine marketing. A lot AI.
This article is a part of a brief collection:
Extra Assets:
Learn Management in search engine marketing. Subscribe now.
Featured Picture: Digineer Station/Shutterstock
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.












