
Enhance your expertise with Progress Memo’s weekly professional insights. Subscribe for free!
For years, SEOs have operated on a easy assumption: The extra floor your content material covers, the extra seemingly it is to floor in AI-generated answers. Actually, each “greatest follow” in basic web optimization content material pushes you towards extra: extra subtopics, extra sections, extra phrases. Construct the “final information.”
An evaluation of 815,000 query-page pairs throughout 16,851 queries and 353,799 pages says in any other case:
- Fan-out protection is practically irrelevant to quotation charges.
- Two alerts really predict whether or not ChatGPT cites your web page.
- Six concrete adjustments to your present content material library assist.
1. The Examine
AirOps ran 16,851 queries by means of ChatGPT 3 times every by means of the UI, capturing each fan-out sub-query, each URL searched, each quotation made, and each web page scraped. Oshen Davidson constructed the pipeline. I analyzed the knowledge.
Every question generates a mean of two fan-out queries. ChatGPT retrieves roughly 10 URLs per sub-search, reads by means of them, then selects which ones to cite. We scored how nicely every web page’s H2-H4 subheadings matched these fan-out queries utilizing cosine similarity on bge-base-en-v1.5 embeddings. That rating is what we name fan-out protection: the share of subtopics a web page addresses at a 0.80 similarity threshold. (The 0.80 similarity threshold cutoff was used to resolve whether or not a subheading counts as a match to a fan-out question. Consider it as a relevance bar.)
The query: Do pages with larger fan-out protection get cited extra?
You’ll discover much more information in the co-written AirOps report.
2. Density Barely Strikes The Needle
Throughout 815,484 rows, the relationship between fan-out protection and quotation is weak.
Protecting 100% of subtopics provides 4.6 proportion factors over protecting none. That hole shrinks additional whenever you management for question match (how nicely the web page’s greatest heading matches the authentic question). Amongst pages with sturdy question match (>= 0.80 cosine similarity):
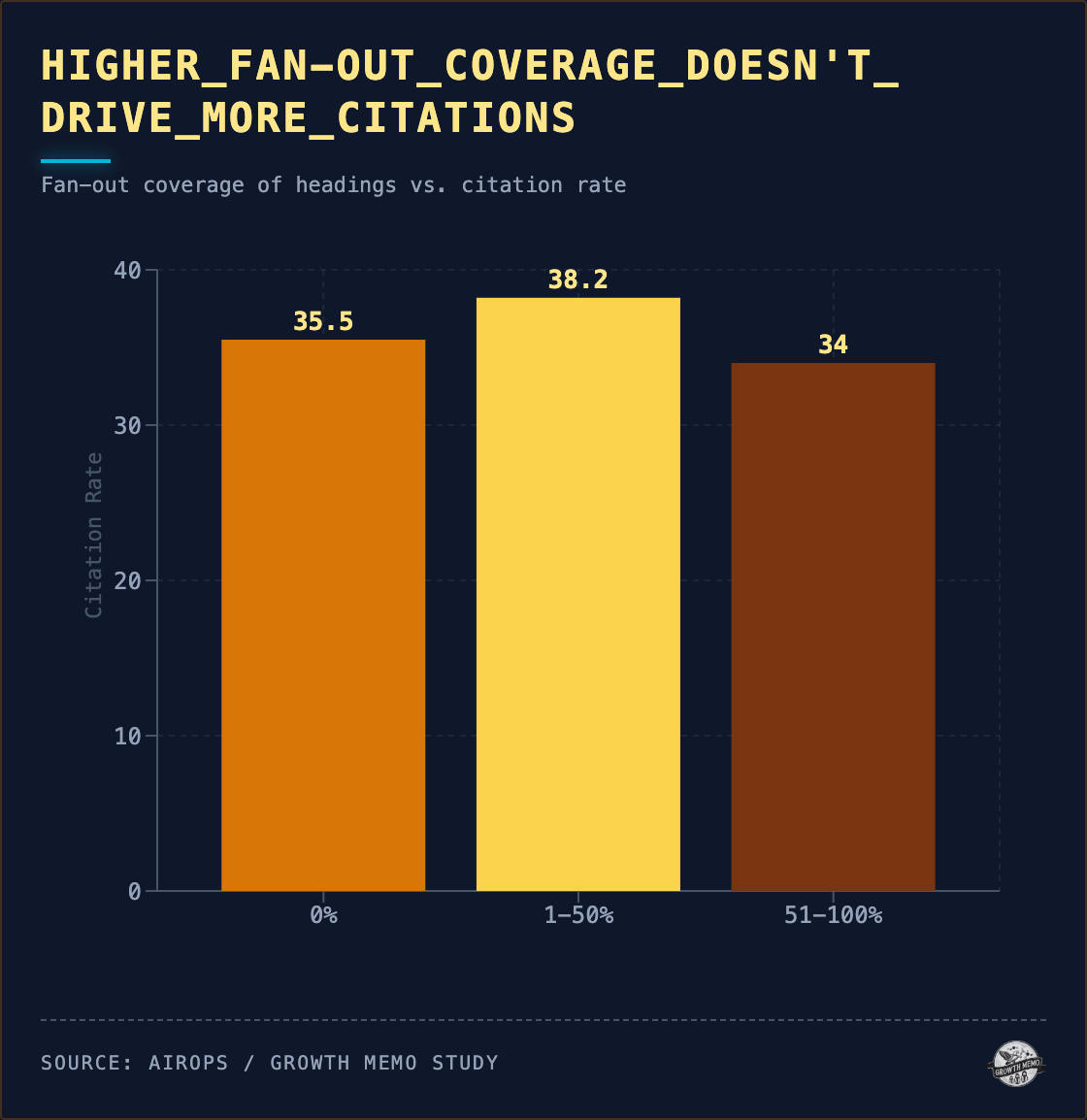
Average protection (26-50%) outperforms exhaustive protection. Pages that cowl all the pieces rating decrease than pages that cowl 1 / 4 of the subtopics. The “final information” technique produces worse outcomes than a centered article that covers two to three associated angles nicely.
3. What Really Predicts Quotation
These two alerts dominate: retrieval rank and question match.
1. Retrieval rank is the strongest predictor by a large margin. A web page at place 0 in ChatGPT’s net search outcomes (the first URL returned by its search device) has a 58% citation rate. By place 10, that drops to 14%. We ran every immediate 3 times consecutively for this evaluation, and pages cited in all three runs have a median retrieval rank of two.5. Pages by no means cited: median rank 13.
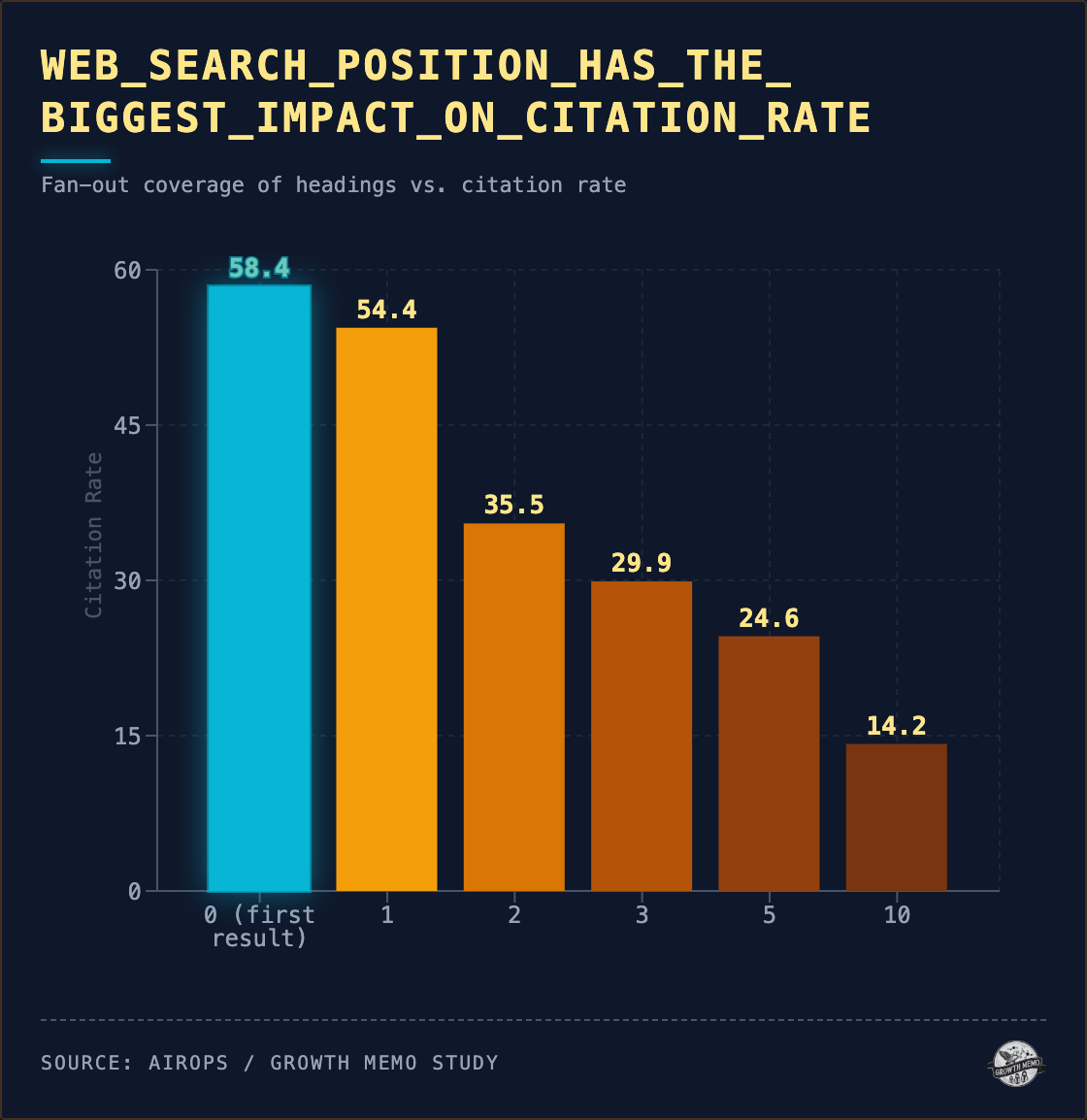
2. Question match (cosine similarity between the question and the web page’s greatest heading) is the strongest content material sign. Pages with a 0.90+ heading match have a 41% quotation fee in contrast to the 30% fee for pages beneath 0.50. Even amongst top-ranked pages (place 0-2), larger question match provides 19 proportion factors.
Fan-out protection, phrase rely, heading rely, area authority: all secondary. Some are flat. Some are inversely correlated.
4. The Wikipedia Exception
One web site sort breaks the sample. Wikipedia has the worst retrieval rank in the dataset (median 24) and the lowest question match rating (0.576). It nonetheless achieves the highest quotation fee: 59%.
Wikipedia pages common 4,383 phrases, 31 lists, and 6.6 tables. They are encyclopedic in the literal sense. ChatGPT cites Wikipedia from deep in the search outcomes the place each different web site sort will get ignored.
This is density working as a sign, however at a scale no writer can replicate. Wikipedia’s content material is exhaustive, richly structured, and cross-linked throughout tens of millions of matters. A 3,000-word company weblog submit with 15 subheadings is not the similar factor.
5. The Bimodal Actuality
58% of pages retrieved by ChatGPT on this dataset are by no means cited. 25% are at all times cited once they seem. Solely 17% fall in between.
The always-cited and never-cited teams look practically equivalent on most content material metrics: related phrase counts (~2,200), related heading counts (~20), related readability scores (~12 FK grade), related area authority (~54). The on-page alerts we will measure do not separate winners from losers.
What separates them is retrieval rank. At all times-cited pages rank close to the prime once they floor. By no means-cited pages rank in the backside half. The retrieval system, no matter alerts it makes use of internally, is the gatekeeper. All the things else is a tiebreaker.
6. What This Means For Your Content material
Standard web optimization content material writing knowledge says cowl extra subtopics, add extra sections, construct density. The information says the standard strategy produces “combined” pages, the 17% in the center that get cited generally and ignored different occasions.
Combined pages have the highest phrase counts, the most headings, and the highest area authority in the dataset. They are the “final guides.” They are additionally the least dependable performers in ChatGPT.
The pages that win persistently are centered. They:
- Match the question instantly of their headings,
- Have a tendency to be shorter (the quotation candy spot is 500-2,000 phrases), and
- Have sufficient construction (7-20 subheadings) to arrange the content material with out diluting it.
Construct the web page that is the greatest reply to one query. Not the web page that adequately solutions 20.
Featured Picture: Tero Vesalainen/Shutterstock; Paulo Bobita/Search Engine Journal
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.














