
Increase your abilities with Development Memo’s weekly knowledgeable insights. Subscribe for free!
In “The Science Of How AI Pays Attention,” I analyzed 1.2 million ChatGPT responses to perceive precisely how AI reads a web page. In “The Science Of How AI Picks Its Sources,” I analyzed 98,000 quotation rows to perceive which pages make it into the studying pool in any respect.
This is Half 3.
The place Half 1 instructed you the place on a web page AI appears to be like, and Half 2 instructed you which pages AI routinely considers, this one tells you what AI truly rewards inside the content material it reads.
The information clarifies:
- Most AI search engine marketing writing recommendation doesn’t maintain at scale. There is no common “write like this to get cited” system – the indicators that raise one trade’s quotation charges can actively harm one other.
- The entity varieties that predict quotation are not the ones being focused. DATE and NUMBER are common positives. PRICE suppresses quotation in 5 of six verticals, and KG-verified entities are a destructive sign.
- The one writing sign that holds throughout all seven verticals: Declarative language in your intro, +14% mixture raise.
- Heading construction is binary. Commit to the proper quantity to your vertical or use none. Three to 4 headings are worse than zero in each vertical.
- Company content material dominates. Reddit doesn’t. AI quotation conduct does not mirror what occurred to natural search in 2023-2024.
1. Particular Writing Alerts Affect Quotation, Whereas Others Hurt It
Whereas “The Science Of How AI Pays Attention” covers elements of the web page and forms of writing that affect ChatGPT visibility, I wished to perceive which writing-level indicators – phrase depend, construction, language type – predict increased AI quotation charges throughout verticals.
Method
- I in contrast high-cited pages (greater than three distinctive immediate citations) vs. low-cited throughout seven writing metrics: phrase depend, definitive language, hedging, record objects, named entity density, and intro-specific indicators.
- I analyzed the first 1,000 phrases for record merchandise depend, named entity density, intro definitive language token density, and intro quantity depend.
Outcomes: Throughout all verticals, definitive phrasing and together with related entities matter. However most indicators are flat.
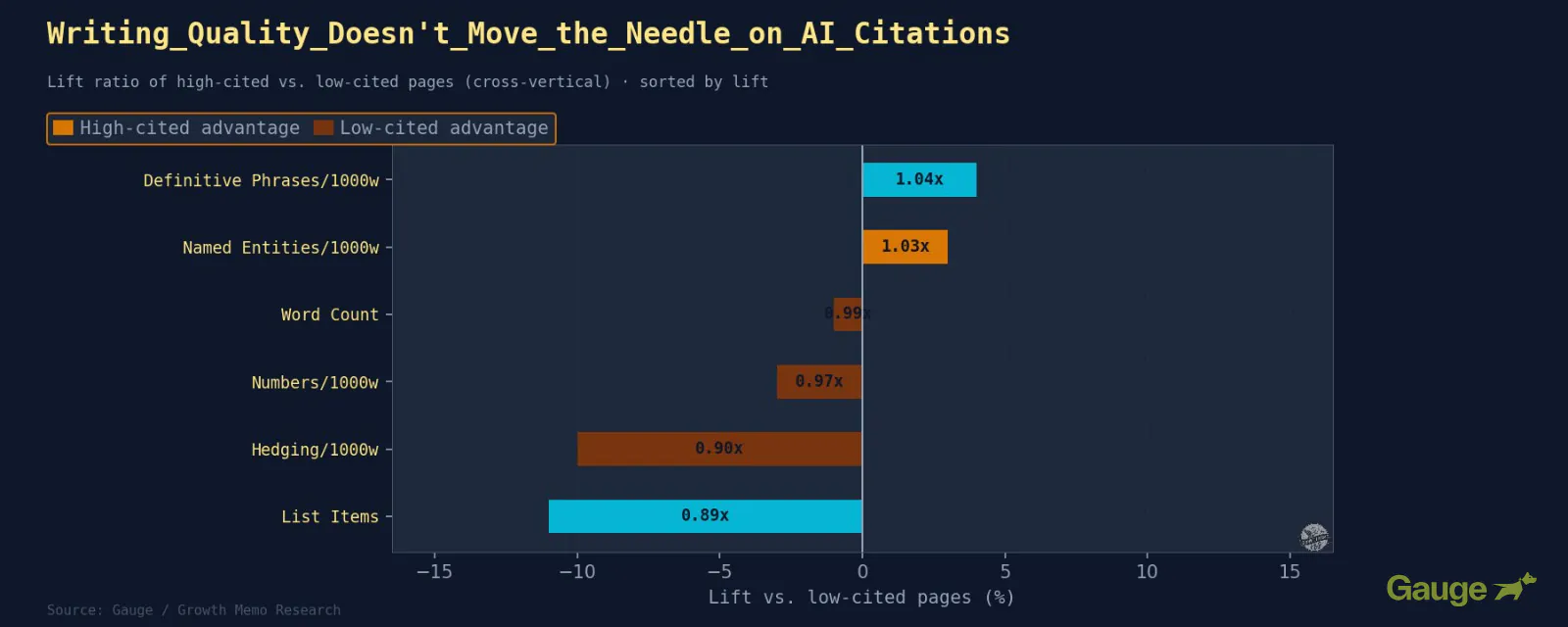
What The Business Patterns Confirmed
When splitting the knowledge up by vertical, we instantly see preferences:
- Complete phrase depend was strongest in CRM/SaaS (1.59x).
- Finance was an anomaly with phrase depend: Shorter pages win (0.86x phrase depend).
- Definitive phrases in the first 1,000 characters had been optimistic for many verticals.
- Training is a sign void. Writing type explains nearly nothing about quotation probability there.

Prime Takeaways
1. There is no common “write like this to get cited” system. For instance, the indicators that raise CRM/SaaS quotation charges actively harm Finance. As an alternative, match content material format to vertical norms.
2. The one common rule: open with a direct declarative assertion. Not a query, not context-setting, not preamble. The shape is “[X] is [Y]” or “[X] does [Z].” This is the solely writing instruction that holds no matter vertical, content material kind, or size.
3. LLMs “penalize” hedging in your intro. “This could assist groups perceive” performs worse than “Groups that do X see Y.” Take away qualifiers from your opening paragraph before some other optimization.
2. The Entity Varieties That Predict Quotation Are Not The Ones Being Focused
Most AEO recommendation focuses on named entities as a class: Pack in additional recognized model names, software names, numbers. The cross-vertical entity kind evaluation under tells a extra particular (and extra helpful) story.
Method
- Ran Google’s Pure Language API on the first 1,000 characters (about 200-250 phrases) of every distinctive URL.
- Computed raise per entity kind: % of high-cited pages with that kind / % of low-cited pages.
- Analyzed 5,000 pages throughout seven verticals.
* A fast word on terminology: Google NLP classifies software program merchandise, apps, and SaaS instruments as CONSUMER_GOOD, a legacy label from when the API was constructed for bodily retail. All through this evaluation, CONSUMER_GOOD means software program/product entities.
Outcomes: DATE and NUMBER are the most common optimistic indicators. Curiously, PRICE is the strongest common destructive.
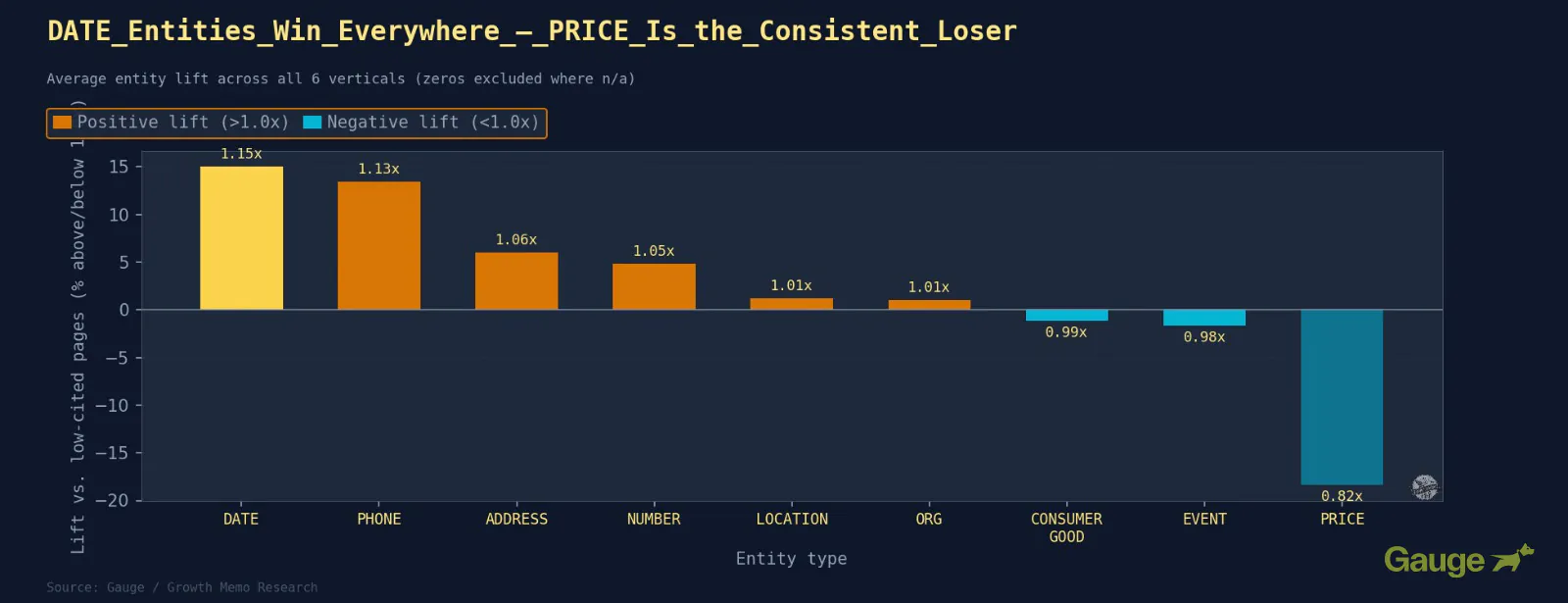
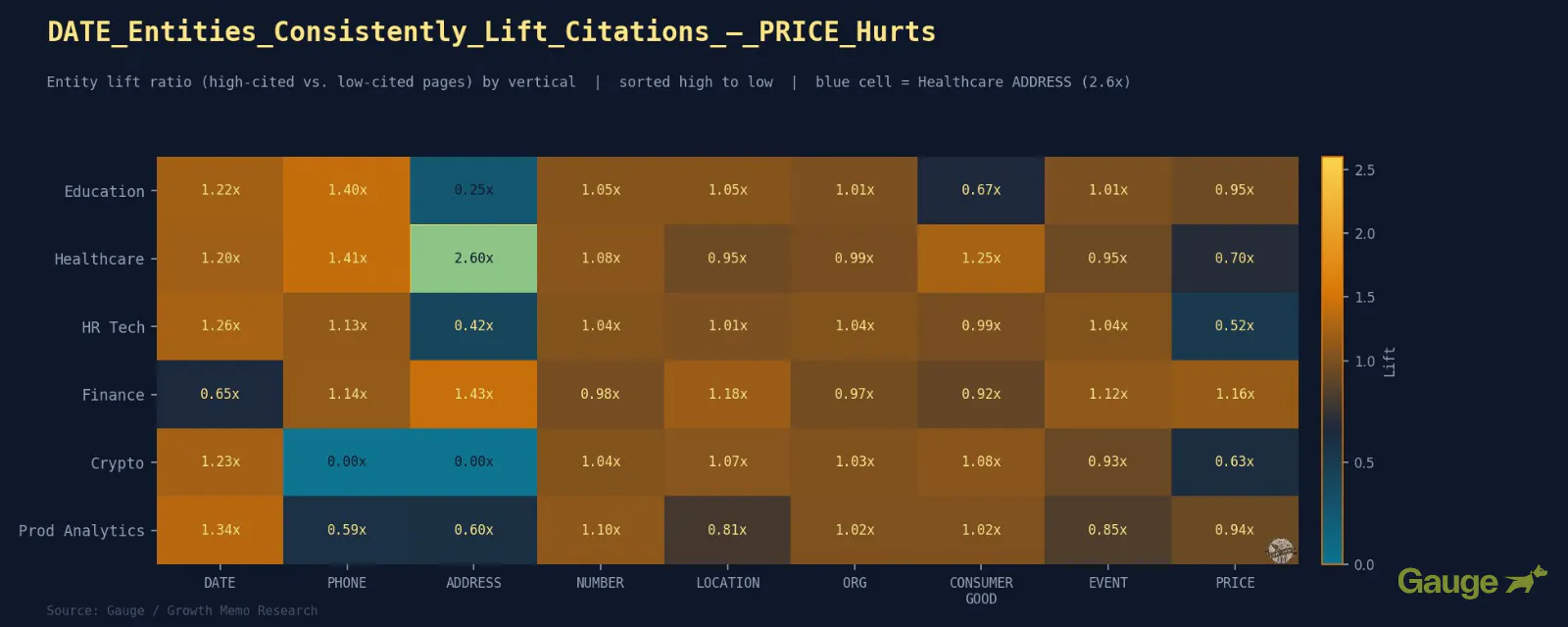
What The Business Patterns Confirmed
- DATE is the most common optimistic sign, with the exception of Finance (0.65x).
- NUMBER is the second most common. Particular counts, metrics, and statistics in the intro constantly predict increased quotation charges. Finance (0.98x) and Product Analytics (1.10x) mark the ground and ceiling of that vary.
- PRICE is the strongest common destructive. Pages that open with pricing sign industrial intent. Finance is the sole exception at 1.16x, seemingly as a result of worth right here means price percentages and fee comparisons, which are the precise reference knowledge monetary queries are on the lookout for.
- CONSUMER_GOOD (software program/product entities) is combined. In Healthcare, product entities sign established manufacturers and instruments. In Crypto, naming particular protocols and merchandise is core to answering technical queries.
- PHONE_NUMBER is a optimistic sign in Healthcare (1.41x) and Training (1.40x). In each circumstances, it is nearly definitely a proxy for established manufacturers/establishments/suppliers with actual bodily presence, not a literal sign to add cellphone numbers to your pages.
The Information Graph inversion deserves its personal word right here:
- The information confirmed that high-cited pages common 1.42 KG-verified entities vs. 1.75 for low-cited pages (raise: 0.81x).
- Pages constructed round well-known, KG-verified entities (main manufacturers, establishments, well-known individuals) have a tendency towards generic protection, which isn’t most well-liked by ChatGPT.
- Excessive-cited pages are dense with particular, area of interest entities: a selected methodology, a exact statistic, a named comparability. Lots of these area of interest entities haven’t any KG entries in any respect. That specificity is what AI reaches for.
Prime Takeaways
1. Add the publish date to your pages and goal to use no less than one particular quantity in your content material. That mixture is the closest factor to a common AI quotation sign this dataset produced. However Finance will get there by means of worth knowledge and site specificity as a substitute.
2. Keep away from opening with pricing in non-finance verticals. Value-dominant intros correlate with decrease quotation charges.
3. KG presence and model authority do not translate to an AI quotation benefit. Chasing Wikipedia entries, model panels, or KG verification is the fallacious lever. Particular, area of interest entities (even ones with out KG entries) outperform well-known ones.
3. Heading Construction: Commit To One Or Don’t Hassle
We all know headings matter for citations from the earlier two analyses. Subsequent, I wished to perceive whether or not heading depend predicts quotation charges and whether or not the optimum construction varies by vertical.
Method
- Counted complete headings per web page (H1+H2+H3) throughout all cited URLs.
- Grouped pages into 7 heading-count buckets: 0, 1-2, 3-4, 5-9, 10-19, 20-49, 50+.
- Computed high-cited fee (% of URLs that are high-cited) per bucket per vertical.
Outcomes: Together with extra headings in your content material is not universally higher. The candy spot relies upon on vertical and content material kind. One discovering holds in every single place: Surprisingly, 3-4 headings are worse than zero.
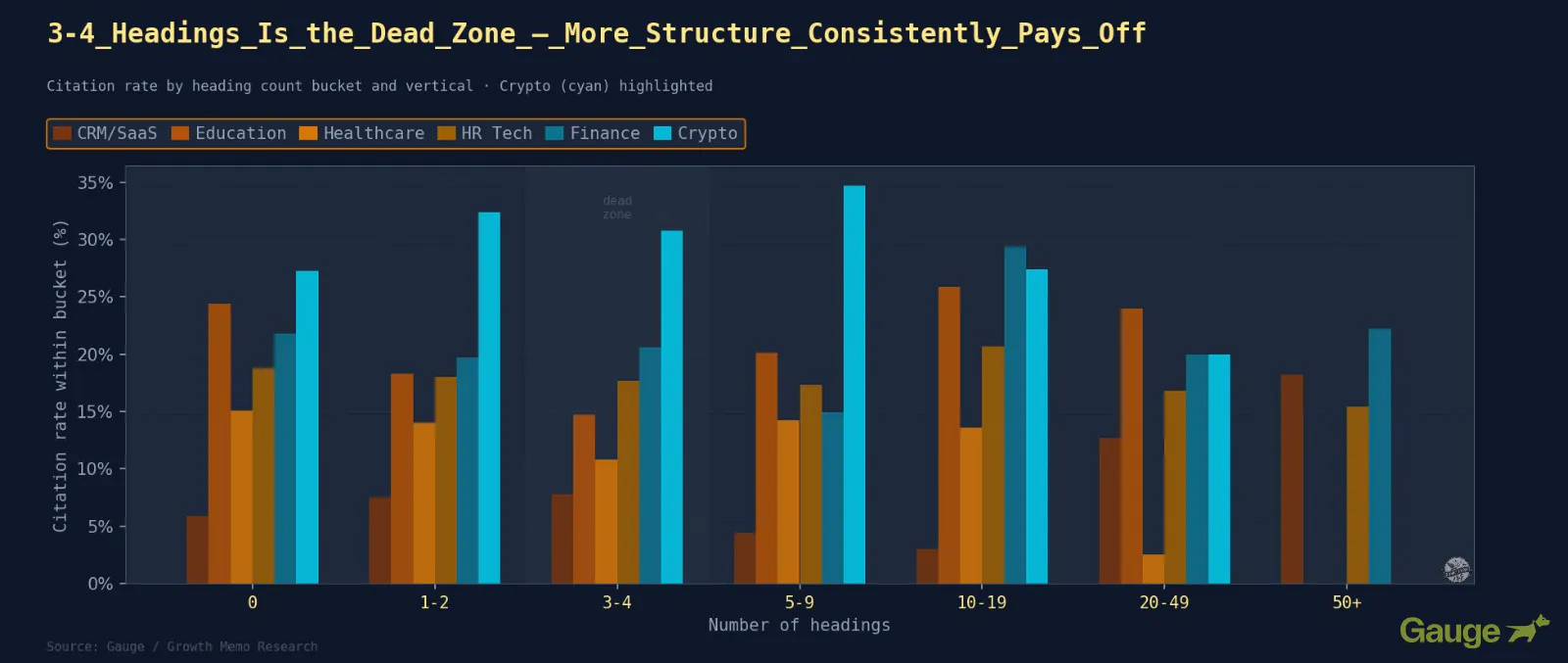
What The Business Patterns Confirmed
- CRM/SaaS is the solely vertical the place the 20+ heading raise is confirmed: 12.7% high-cited fee at 20-49 headings vs. a 5.9% baseline. The 50+ bucket reaches 18.2%. Lengthy structured reference pages and comparability guides with one part per software outperform the whole lot else right here.
- Healthcare inverts most sharply. The high-cited fee drops from 15.1% at zero headings to 2.5% at 20-49 headings. A web page with 30 H2s on telehealth matters indicators optimization intent, not scientific authority.
- Finance peaks at 10-19 headings (29.4% high-cited fee). Structured however not exhaustive: suppose fee tables, regulatory breakdowns, and advisor comparability pages with average heading depth.
- Crypto peaks at 5 to 9 headings (34.7% high-cited fee). Technical documentation on this vertical tends towards dense prose with average navigation construction. Over-structuring breaks up the technical depth.
- Training is flat throughout all heading counts, which is in keeping with the writing indicators discovering. Heading construction explains nearly nothing about quotation probability in schooling content material.
- The three to 4 heading useless zone holds throughout each vertical with out exception. Partial construction confuses AI navigation with out offering the full advantage of a dedicated hierarchy.
Prime Takeaways
1. The 20+ heading discovering from Half 1 is a CRM/SaaS discovering, not a common one. Making use of it to healthcare, schooling, or finance might actively suppress quotation charges in these verticals.
2. The precept that holds in every single place: Commit to construction or don’t use it. The center floor prices you in each vertical. A completely-structured web page with the proper heading depth outperforms a half-structured web page in each vertical.
3. Use the optimum heading vary to your vertical. Crypto: 5-9. Finance and Training: 10-19. CRM/SaaS: 20+ (with H3s). Healthcare: 0 or 5-9 at most. Lengthy CRM reference pages with 50+ sections are the one case the place most heading depth pays off.
4. UGC Doesn’t Dominate
The “Reddit impact” reshaped natural search between 2024 and 2025. I wished to perceive whether or not ChatGPT cites user-generated content material (Reddit, boards, critiques) at significant charges or whether or not company/editorial content material dominates.
The frequent trade assumption – that AI additionally preferentially cites neighborhood voices – is not what we present in the knowledge.
Method
- Categorised these cited URLs as (1) UGC: Reddit, Quora, Stack Overflow, discussion board subdomains, Medium, Substack, Product Hunt, Tumblr, or (2) neighborhood/discussion board prefixes or company/editorial by area.
- Computed quotation share per class per vertical.
- Dataset: 98,217 citations throughout 7 verticals.
Outcomes: Company content material accounts for 94.7% of all citations. UGC is practically invisible.
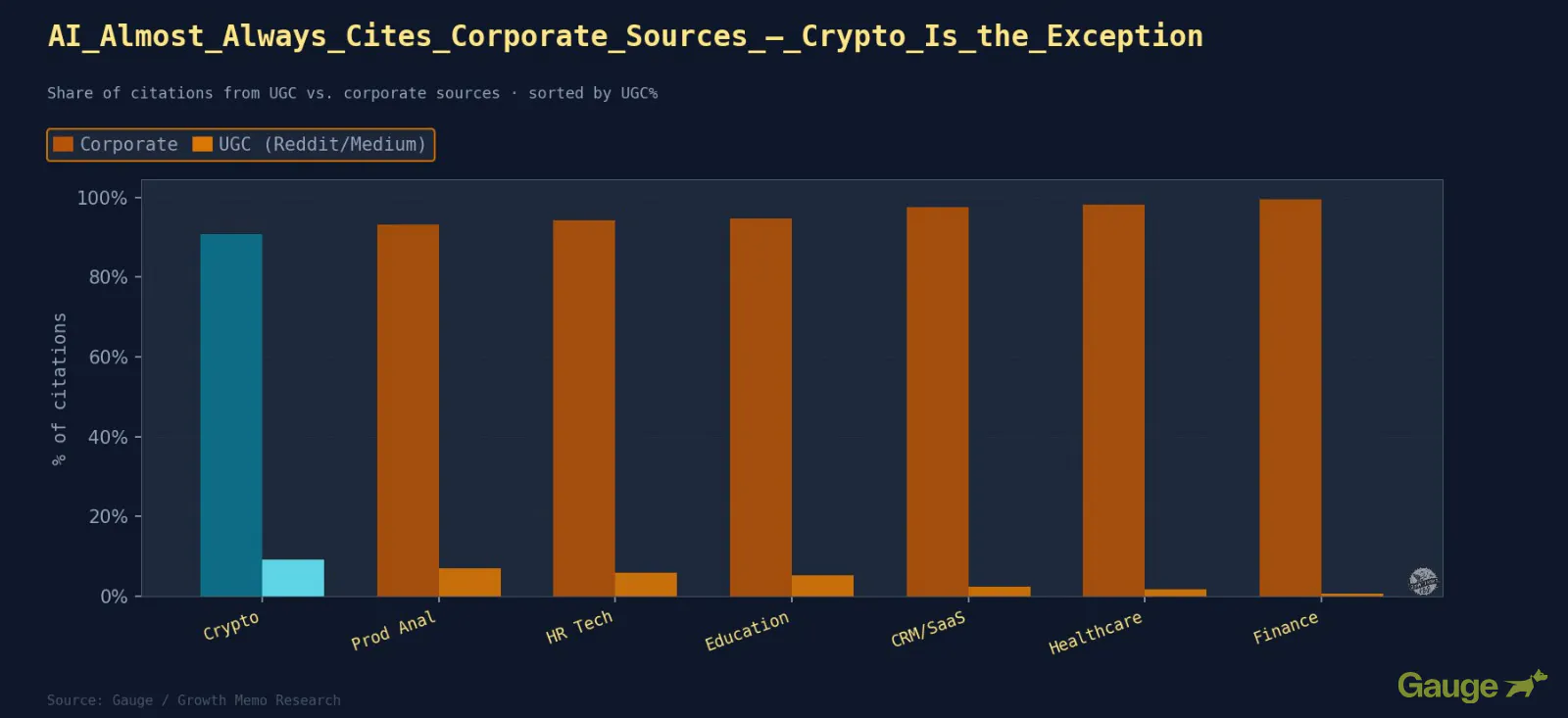
What The Business Patterns Confirmed
- Finance is the most corporate-locked vertical at 0.5% UGC. YMYL (Your Cash, Your Life) content material seems to systematically suppress citations to neighborhood opinion.
- Healthcare sits at 1.8% UGC for the identical structural purpose. Scientific, telehealth, and HIPAA content material attracts nearly completely from institutional sources.
- Crypto has the highest UGC penetration in the dataset at 9.2%. Group-generated content material (Reddit technical threads, Medium tutorials, developer discussion board posts) solutions a significant proportion of analyzed queries. In a fast-moving technical area of interest the place official documentation constantly lags, neighborhood posts fill the hole.
- Product Analytics and HR Tech sit at 6.9% and 5.8% UGC. Each are verticals the place Reddit comparability threads and product evaluation communities present real sign alongside company content material.
Prime Takeaways
1. The “Reddit impact” in search engine marketing has not translated proportionally to AI citations. In most verticals, reddit.com captures 2-5% of complete citations. This discovering is consistent with different trade analysis, together with this report from Profound.
2. For finance and healthcare: UGC has near-zero AI quotation worth. Spend money on structured, authoritative company content material with clear sourcing. Group engagement could matter for different causes, but it surely does not contribute meaningfully to AI quotation share in these verticals.
3. For crypto, product analytics, and HR tech: Group presence has measurable quotation worth. Detailed Reddit comparability threads, technical Medium posts, and structured developer discussion board solutions can complement company content material attain.
What This Means For How You Strategize For LLM Visibility
Throughout all three elements of this research, the constant discovering is that AI quotation is not primarily a writing high quality drawback.
Half 2 confirmed it is a content material structure drawback: Skinny single-intent pages are structurally locked out no matter how effectively they’re written. This piece reveals the identical logic applies inside the content material itself.
The combination writing indicators desk is the most essential chart on this evaluation. Not as a result of it reveals you what to do, however as a result of it reveals how a lot of what the AI search engine marketing/GEO/AEO trade is telling you doesn’t survive cross-vertical scrutiny. Phrase depend, record density, named entity counts … all flat or destructive at the mixture. The indicators that work are vertical-specific and smaller than our trade’s consensus implies.
The meta-lesson from this evaluation is that findings are vertical (and doubtless subject) particular, which is no totally different in search engine marketing.
This half concludes the Science of AI – for now. As a result of the AI ecosystem is continually altering.
Methodology
We analyzed ~98,000 ChatGPT quotation rows pulled from roughly 1.2 million ChatGPT responses from Gauge.
As a result of AI behaves in another way relying on the subject, we remoted the knowledge throughout seven distinct, verified verticals to guarantee the findings weren’t skewed by one particular trade.
Analyzed verticals:
- B2B SaaS
- Finance
- Healthcare
- Training
- Crypto
- HR Tech
- Product Analytics
Featured Picture: CoreDESIGN/Shutterstock; Paulo Bobita/Search Engine Journal
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.














