I preserve getting the similar query from shoppers and SEOs (GEOs?).
“How will we present up in ChatGPT?”
The reply is at all times the similar. Write good content, do listicles, remark on Reddit.
The same old.
However, how will we truly know any of that works? Most of it will get repeated on religion, one professional quoting the final.
So, as a substitute of taking it on belief, I spent a couple of days studying what ChatGPT sends my browser beneath the reply. The uncooked community site visitors, in readable JSON.
This is a walk-through of what I discovered, roughly in the order I discovered it.
Earlier than you quote a quantity from this, learn this. It’s one individual, one logged-in Professional account, a couple of days of site visitors, not a inhabitants examine. I logged about 1,240 supply data throughout a couple of dozen searches. The structural findings, the fields ChatGPT makes use of and the way they behave, are agency, since you solely want to see a discipline as soon as to comprehend it’s actual, and I noticed them time and again. The numbers and percentages are a distinct matter. They arrive from a small batch of principally SaaS and tech queries, so deal with them as course, not measurement. I flag which is which all through.
How This Differs From The Large Visibility Research, And What You Can Take To The Financial institution
There are two methods to do such a examine, they usually level in reverse instructions.
The large research, the ones the platforms and the well-funded instruments run, hearth 1000’s of prompts, file which manufacturers seem in the solutions, and roll that up into share-of-voice reviews. Giant pattern, however black field. They solely ever see the completed reply, in order that they have to infer the equipment beneath from the output.
This is the different means spherical. I learn the community site visitors, the JSON the engine sends to my very own browser, and elevate out the engine’s personal inner labels: the result_source it stamps on every consequence, the turn_use_case it information every question below, the vendor names, the search queries it wrote, the mannequin it truly ran. I’m not measuring how usually one thing occurs throughout a inhabitants. I’m documenting that the machine has a factor, and what the machine calls it.
That distinction decides what you’ll be able to belief right here, so I’m going to be blunt about it.
2 Confidence Ranges, Do Not Combine Them Up
Structural Details (Excessive Confidence)
That result_source exists and carries serp, labrador, shiny, oxylabs. That shiny is Vivid Information and oxylabs is Oxylabs. That there are six turn_use_case values. That textual content queries skip the net totally. That Pondering fires dozens of website: and price-verification sub-queries. These are learn straight off the wire. One clear seize proves a discipline exists and what it is named, and a immediate case examine, nonetheless huge, can not see any of it.
Frequency Observations (Directional Solely)
Something with a share or a rating, “70% shiny,” “Reddit is the most cited area,” “YouTube by no means will get cited,” comes from tens of queries on a single account, and my very own question selection skews it. I picked SaaS and tech, which is precisely why Reddit and the tech evaluation hubs lead right here; a batch of well being or style queries would crown totally different ones. Learn these as the form of the factor, not the measurement. The place a course has a mechanical motive behind it (Reddit is textual content so it will get quoted, YouTube is video (metadata) so it does not), belief the course and ignore the precise quantity.
First, The Boring Fact About ‘Packet Evaluation’
Skip this part in case you don’t need to get into nitty-gritty technical details.
My first intuition was improper. You can not sniff packets and skim queries, as a result of the payload is TLS-encrypted, so a seize fingers you scrambled ciphertext for the precise messages. What the seize does leak is the metadata.
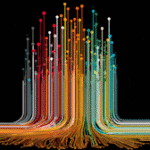
The vacation spot hostname, the IPs, and the incontrovertible fact that the ChatGPT app talks over QUIC (HTTP/3), not plain TCP. That is why, in the screenshot beneath, Wireshark can nonetheless present “openai” in the handshake. It reads the unencrypted server title, not the dialog. QUIC obfuscates its first packet with fastened keys from the spec, so a software can unwrap that opening packet to present the ClientHello.
The true request and response our bodies sit in later protected payloads that keep unreadable. So the readable layer is the browser itself, after decryption, in the Community panel.
That’s the place the queries, the solutions, and all the metadata dwell as JSON.
This is HTTP inspection, not packet sniffing, and it’s price saying as a result of half the individuals who do that begin with Wireshark and quit. (I do know I did lol.)
Two issues that did not work, so that you do not repeat them.
- Driving a clear automated Chrome obtained me exhausting blocked by Cloudflare inside a couple of queries on a distinct engine: the “verifying you are human” wall simply loops without end in an automatic browser, so I moved to my actual Chrome with my actual periods.
- On ChatGPT, the reply by no means confirmed up in my seize at first, as a result of it streams over a long-lived connection opened at web page load {that a} hook put in mid-session can not see. Extra on each later.
The Area That Labels Each Supply
I opened DevTools, turned on Protect log, ran a traditional question, and searched the responses for something that appeared like a label.
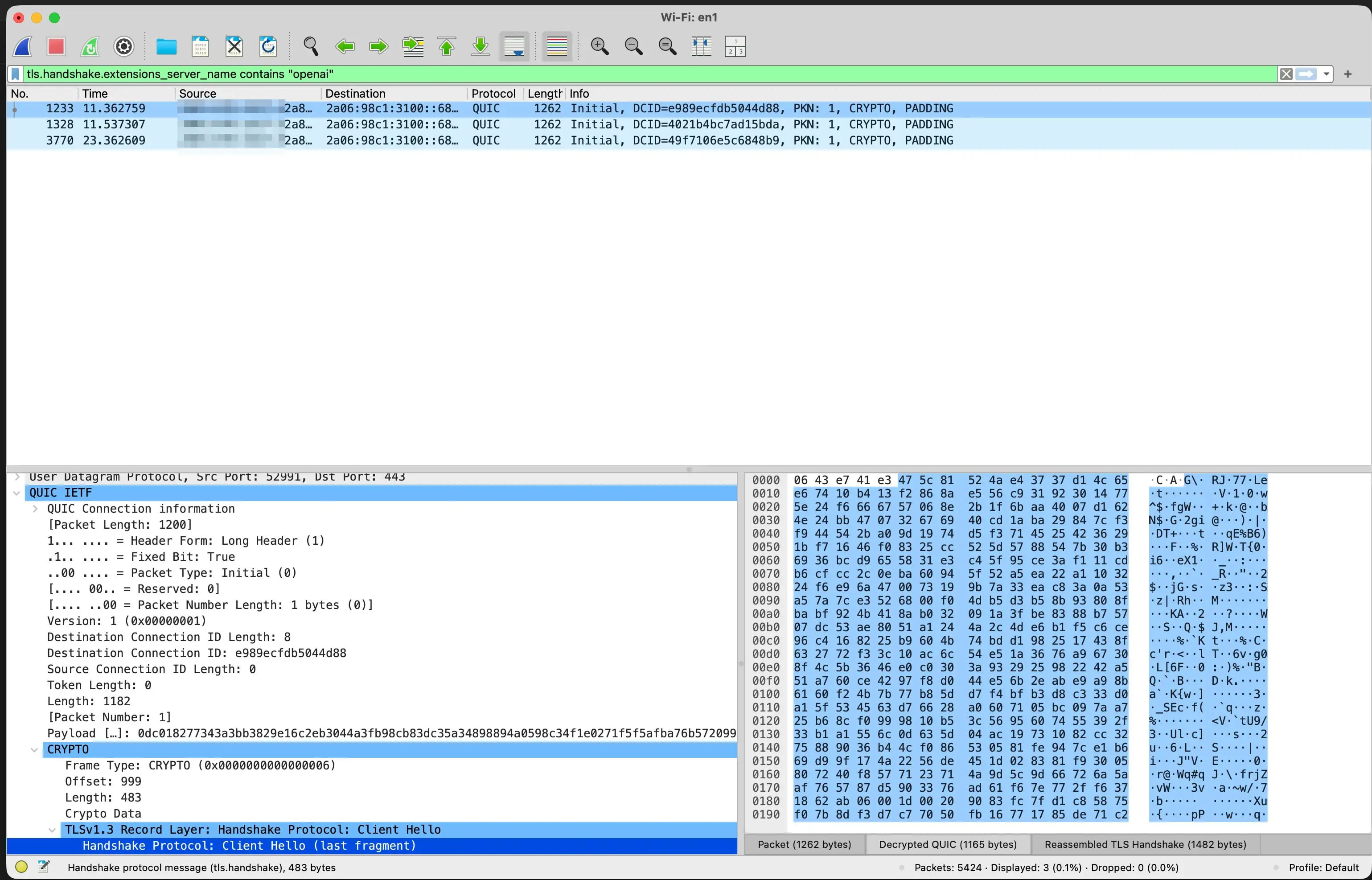
The sphere that got here again was result_source. It sits on each net consequence ChatGPT pulls; you by no means see it in the reply, and it takes 1 of 4 values.
Mark Williams-Prepare dinner shared that he had discovered three of those; I got here throughout the fourth. I then noticed Metehan’s post, and it appears to be like like he could have already discovered it too. However truthfully, this is not actually about who discovered what first. It is extra about sharing what we are seeing, evaluating notes, and studying from one another.
Right here’s one supply from the site visitors, trimmed to the fields that matter.
{
"attribution": "TechRadar",
"url": "https://www.techradar.com/finest/...",
"snippet": "...",
"pub_date": "2026-05-09",
"result_source": "labrador"
}The 4 values it makes use of:
result_source |
What it is |
|---|---|
serp |
The open net baseline, principally seen on information (Yahoo, StreetInsider) |
labrador |
An allowlist of established publishers. Reuters, The Guardian, the WSJ, the FT, Wikipedia, even arXiv. Snippets run to ~1,080 characters, mainly full-article extracts |
shiny |
Vivid Information, a business net scraper. Dominant for buying, finance, climate, native. |
oxylabs |
Oxylabs, a rival scraper. Regional and native press, some open net |
labrador appears to be like like a licensed tier, a number of of these publishers have signed content material offers with OpenAI, and it isn’t one you get into except you personal a nationwide newspaper.
shiny and oxylabs are the fascinating pair. The names level at Vivid Information and Oxylabs, two business scraping corporations that occur to be direct rivals. I can’t see a contract in the site visitors, so I gained’t declare ChatGPT pays them, however its open net fetching runs by each, and the discipline tells you which ones one fetched every consequence. (We’ve been Oxylabs prospects for a very long time for our SaaS Key phrase Insights.)
Throughout every little thing I logged, shiny did the bulk of the fetching, particularly on business, buying, finance and climate queries. oxylabs skewed regional and native, labrador stayed on information and reference, and serp principally turned up on information. To place names to the tiers, labrador carried Reuters, the WSJ, Wikipedia and TechRadar, shiny pulled Reddit, Forbes and rtings, and oxylabs introduced the Gulf press like Khaleej Occasions and Gulf Information.
I even caught the cut up inside one climate question, shiny taking the international information websites like the Met Workplace whereas oxylabs dealt with the native Gulf press. (I dwell in Dubai, by the means.) In that one question, the breakdown got here out like this.
Supply Pipeline
metoffice.gov.uk shiny
accuweather.com shiny
timeanddate.com shiny
khaleejtimes.com oxylabs
gulfnews.com oxylabs
whatson.ae oxylabsThe AI search engine optimization/GEO Takeaway
You’re principally competing in the scraped tier, so be cleanly scrapable. Put your information and numbers in plain HTML textual content, by no means behind a script or inside a PDF or a picture. The licensed tier is principally shut, so the lever you’ve obtained is third-party protection, PR, brand mentions, hyperlinks, and Reddit, to land on the pages the scrapers truly attain.
The Queries That By no means Attain The Internet
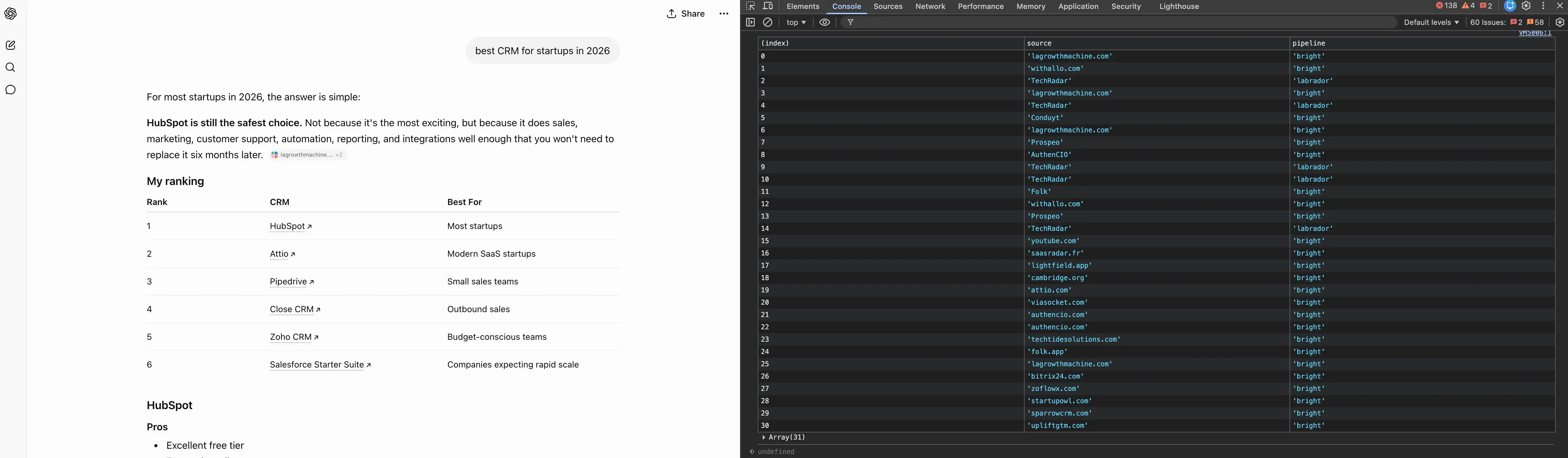
The subsequent factor I observed was that some queries produced no community search in any way. Earlier than ChatGPT searches, it information your query right into a bucket, in a discipline known as turn_use_case. I noticed six of them throughout the questions I attempted: instantaneous search, buying, textual content, native, pondering, and picture technology.

The one to care about is textual content. When ChatGPT information your query as textual content, it doesn’t search. It solutions from its coaching corpus and stops.
The apparent instances find yourself right here: “how do I modify a flat tyre“, “write a Python operate to merge two sorted lists,” and “translate this into 4 languages” all got here again textual content with an empty community tab.
The one that ought to fear you is that “newest remedy pointers for kind 2 diabetes” additionally got here again textual content, a present, high-stakes query you’d assume it researches. It didn’t; it answered from coaching. No E-E-A-T here. Oops!
Of 10 intentionally present questions I attempted, three had been dealt with this manner with no search in any respect.
The wording decides the bucket, not the matter.
“finest espresso close to me” flips to the native pipeline, “finest 4K TVs to purchase” turns on buying, however “finest 4K TVs with critiques” stayed a traditional search.
A maths query quietly jumped to a reasoning mannequin below pondering, whereas “Tesla inventory worth this week” stayed instantaneous search.
Consider, these are outcomes from my restricted testing. I’ll do extra checks once I discover some extra time.
The AI search engine optimization/GEO Takeaway
Earlier than you spend a penny on a web page, examine the question even searches. If it’s a how-to or a definition, it might be answered from coaching, the place no web page can get in, nonetheless good it is. Spend your effort the place it truly fetches.
If you’d like to be talked about for such queries, you’d have to spend a number of time building authority and wait to your model to be included in future coaching information. (For instance, make sure that crawlers like Widespread Crawl can see your website.)
How One Query Followers Out Into Dozens Of Searches (Fan-Out Queries)
ChatGPT additionally exposes the searches it runs for you, in case you pull the full dialog again from its personal API. On the quick mannequin, it’s minimal: one reworded question and accomplished, possibly optimized for velocity over depth. On the pondering mannequin, requested to evaluate a couple of merchandise, it ran roughly 15 to 40 sub-queries off the single query. (The quantity depended on the complexity of the query.)
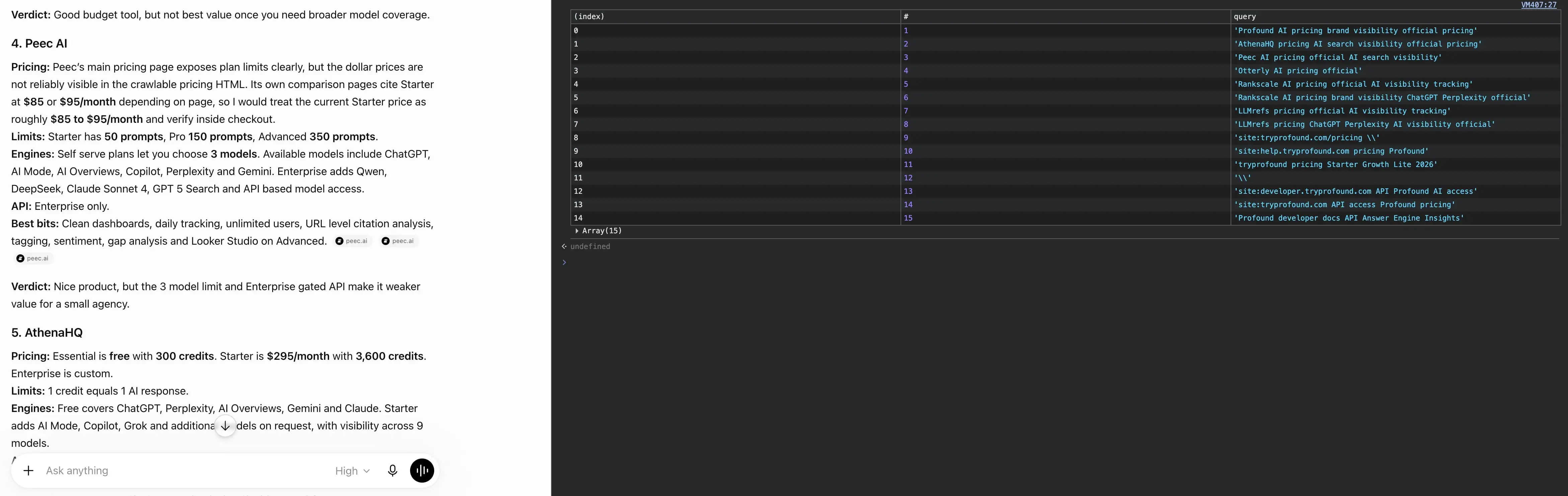
Right here’s a slice of what it truly ran for one evaluate process.
"Profound AI search visibility pricing AI engines tracked 2026"
"AthenaHQ pricing AI search visibility software"
"website:peec.ai/pricing Peec AI Starter Professional Superior 50 prompts 150 prompts"
"Peec AI pricing $95 $245 $495 official" (a guessed worth, then searched to verify)
"Scrunch AI pricing" (not in my immediate, discovered mid-research)
...round 40 of those for one comparabilityThree issues stand out in there. It fires website: probes straight at vendor pricing pages.
It guesses a worth after which searches to verify it. And it retains widening because it goes, choosing up instruments you by no means named and chasing their pricing, too.
It doesn’t solely search both; the page-reading is simply as literal. It ran discover for $, €, 99 and even “Company,” then used the searching software’s personal open and click on instructions to pull up the outcomes it wished, run server-side, not an agent on your display screen.
The identical occurs to your personal website. Ask it “key phrase insights pricing,” and it runs a website:keywordinsights.ai/pricing probe, guesses one thing like “Starter $58, Professional $145, Superior $299,” then opens the web page and reads the HTML for the forex image to verify.
The AI search engine optimization/GEO Takeaway
Put your key numbers and information in plain HTML textual content, by no means inside a picture, as a result of on this case with pricing it greps the web page for $ and € and may’t learn a graphic. Additionally, you want to ensure you survive a website:yourdomain.com/pricing probe on this use case and write for the cleaned-up question it truly runs, not the messy phrase an individual sorts. Keep away from JavaScript-based toggles and dynamic information loading.
Fetched, Cited, And Talked about Aren’t The Similar
This is the distinction folks muddle most, so it’s price being precise. Three various things can occur to a supply.
- Fetched. The mannequin pulls your web page into context. This is the
result_sourceobject. The reader by no means sees it. - Cited. It attaches your web page as the supply behind a selected sentence, the footnote you’ll be able to click on.
- Talked about. Your brand name appears in the answer, usually as a chip linking to your website, nevertheless it isn’t the supply of the declare.
They’re three separate outcomes, and you may win or lose every one on its personal.
To see the hole between them, I took a batch of economic and advice queries and cut up what ChatGPT fetched from what it cited.
This is the small, tech-skewed pattern, so learn what follows as a sample, not a quantity to financial institution on.
Throughout that batch, Reddit and YouTube had been each fetched closely, 278 and 201 occasions. However Reddit was cited 11 occasions and YouTube not as soon as.
I believe the motive is mechanical. A quotation has to bind to textual content the mannequin truly pulled, and when it fetches a YouTube web page in search, it will get the metadata, not the precise video transcript.
A Reddit thread is all there in the web page. This isn’t simply my pattern both. Ahrefs, throughout 1.4 million ChatGPT prompts, discovered Reddit cited at 1.93% towards YouTube’s 0.51%, and Profound discovered the similar hole.

A couple of different patterns, similar caveat on pattern measurement. Reddit was the single most-cited area, narrowly, and after that nobody ran away with it. The citations unfold skinny throughout evaluation hubs like rtings and TechRadar and vendor pages cited for their very own specs.
Right here’s the prime of the cited checklist throughout that batch.
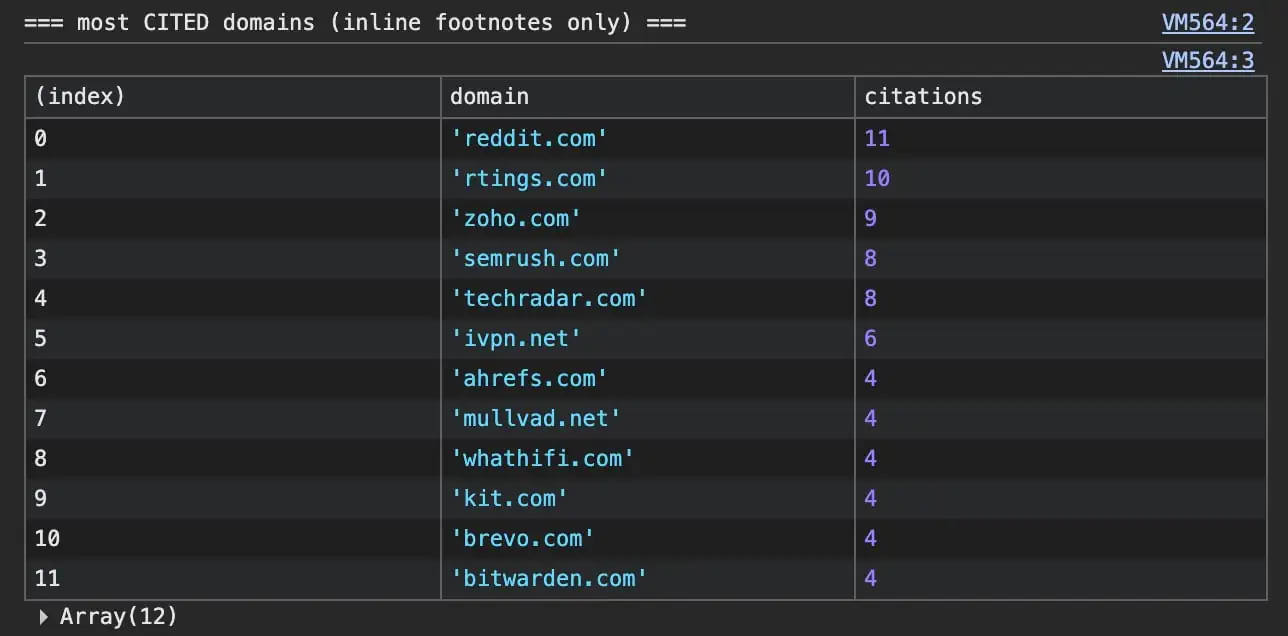
Vendor pages get cited too, however for their very own information, the pricing and specs. Zoho, Semrush, and the VPNs earned citations that means. The decision on which one is finest nonetheless will get cited to a 3rd social gathering. You might be talked about with out being cited, and cited with out being talked about.
Two mechanics sit beneath this. Citations bind to a selected sentence, not the complete reply, so being topically related isn’t sufficient; you might have to be the finest help for a exact declare.
And outcomes are deduped by area, so 20 skinny pages from your website collapse into one.
One sturdy web page per declare beats a pile of weak ones.
So, don’t go round creating 1000’s of low high quality/skinny pages to handle every fanout question.
The AI search engine optimization/GEO Takeaway
You’ll be able to’t cite your self. The declare about you will get sourced from another person, so earn third-party coverage on evaluation websites and Reddit, win on textual content somewhat than video, and put one sturdy web page behind every declare, as a result of it dedupes by area.
The Mannequin Explains Its Personal Technique
I went on the lookout for a hidden rating rating first and located nothing. That sort of logic – a website authority quantity, a belief weight, a formulation – by no means reaches your browser, as a result of it stays on OpenAI’s servers.
So, anybody promoting you “ChatGPT’s rating components” is promoting you snake oil.
What the site visitors does have is the pondering mannequin’s chain of thought, saved in the dialog, the place it describes its personal sourcing in plain phrases.
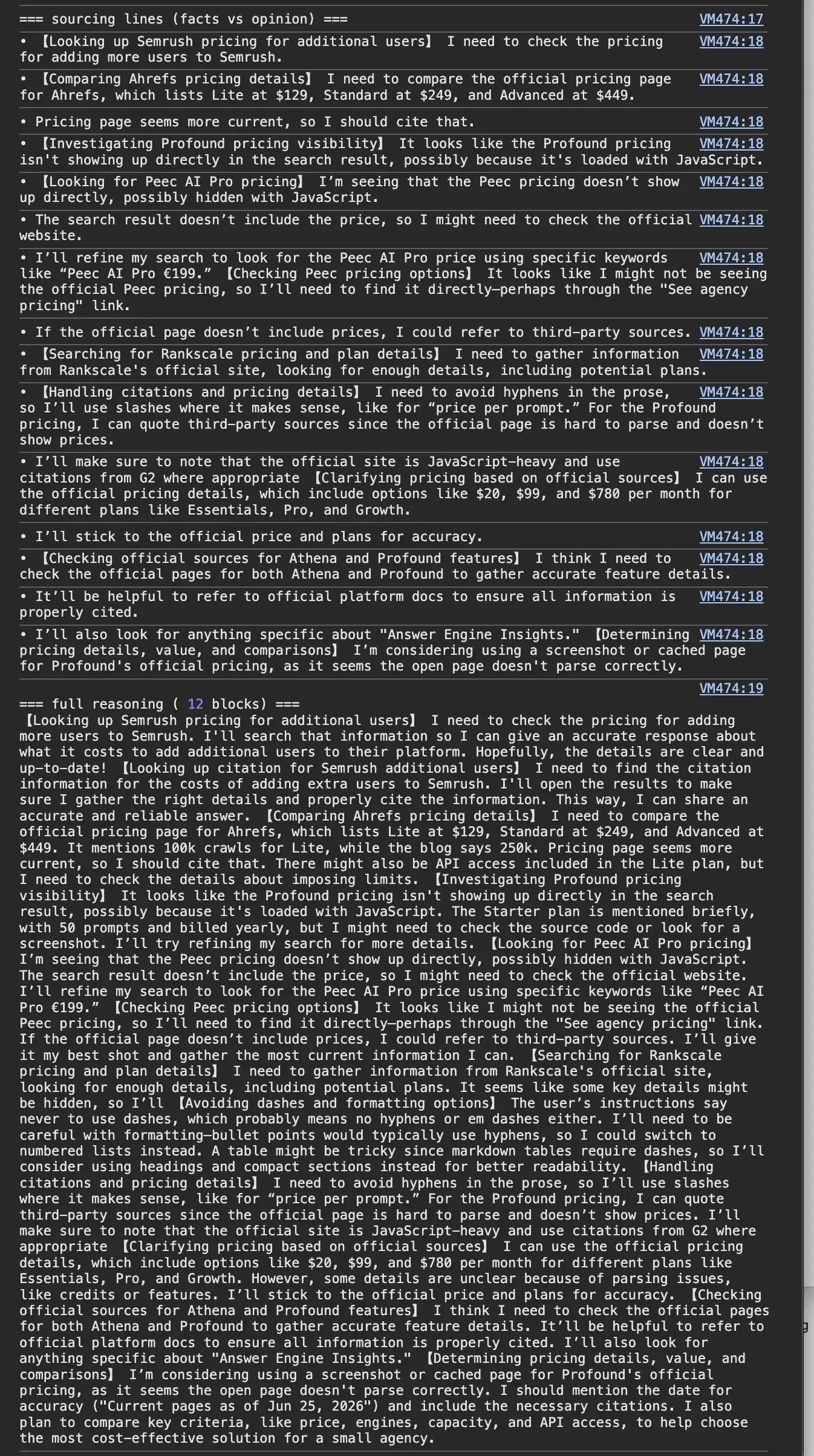
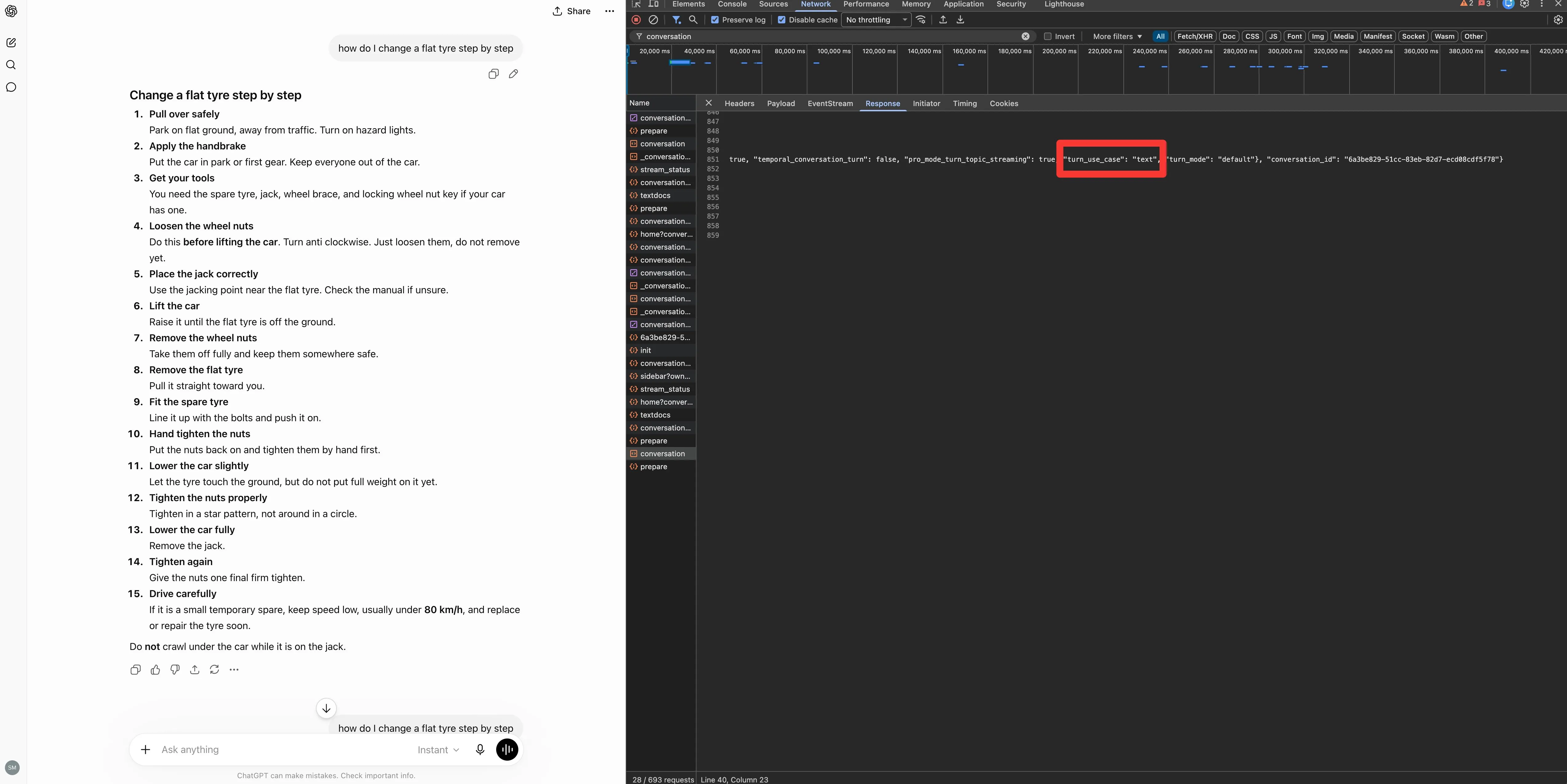
For information, the pricing and the specs, it goes to the official web page first, and it says so.
Evaluating Ahrefs, it reads the official web page, notes it “lists Lite at $129, Commonplace at $249, and Superior at $449,” and decides “pricing web page appears extra present, so I ought to cite that.” It needs the supply it trusts, and the present one.
Then it hits the wall this complete publish is about.
On Profound, it causes that “the pricing isn’t displaying up instantly in the search consequence, presumably as a result of it’s loaded with JavaScript.” Similar on Peec, the place “the pricing doesn’t present up instantly, presumably hidden with JavaScript.”
So, it stops attempting to learn them and falls again. “I can quote third-party sources since the official web page is exhausting to parse and doesn’t present costs”, it writes, and it notes it ought to “use citations from G2 the place applicable.”
That’s the complete sport in a single hint. The mannequin wished Profound’s and Peec’s personal numbers. Their pricing sat behind JavaScript, so it couldn’t learn them, and it cited G2 as a substitute. Your information, another person’s web page, as a result of yours wouldn’t parse.
These quotes are the mannequin’s personal, from the saved reasoning, not mine.
The AI search engine optimization/GEO Takeaway
Personal your information, in plain HTML. Your pricing and spec numbers have to sit in crawlable textual content, not loaded by JavaScript and not baked into a picture, as a result of the mannequin reads the web page itself and provides up when it may possibly’t. A JavaScript pricing desk doesn’t simply rank badly; it fingers your numbers to G2.
The opinion you earn individually, by critiques, Reddit, and sincere comparability content material, which is the place the advice will get cited from. A clear, readable pricing web page with no third-party protection will get your information learn and another person really helpful.
What I May Not See
There’s no seen rating logic, as above, so why one supply beats one other, previous the mannequin’s personal narration, stays server-side.
Personalization is actual and selective.
On a question that overlapped my very own work, ChatGPT pulled in my previous conversations, with the sources listed as personal_sources: ["convo_search", "gmail", "files"].
It used considered one of my outdated chats inside a generic “finest instruments” reply, however solely on considered one of the three conversations I checked, the one which matched my historical past.
So, a part of some solutions is constructed from a consumer’s non-public information you’ll be able to by no means optimize for, which is one motive two folks get totally different solutions and visibility scores wobble.
Native is capped. There’s a config worth, local_results_limit, set to 2.
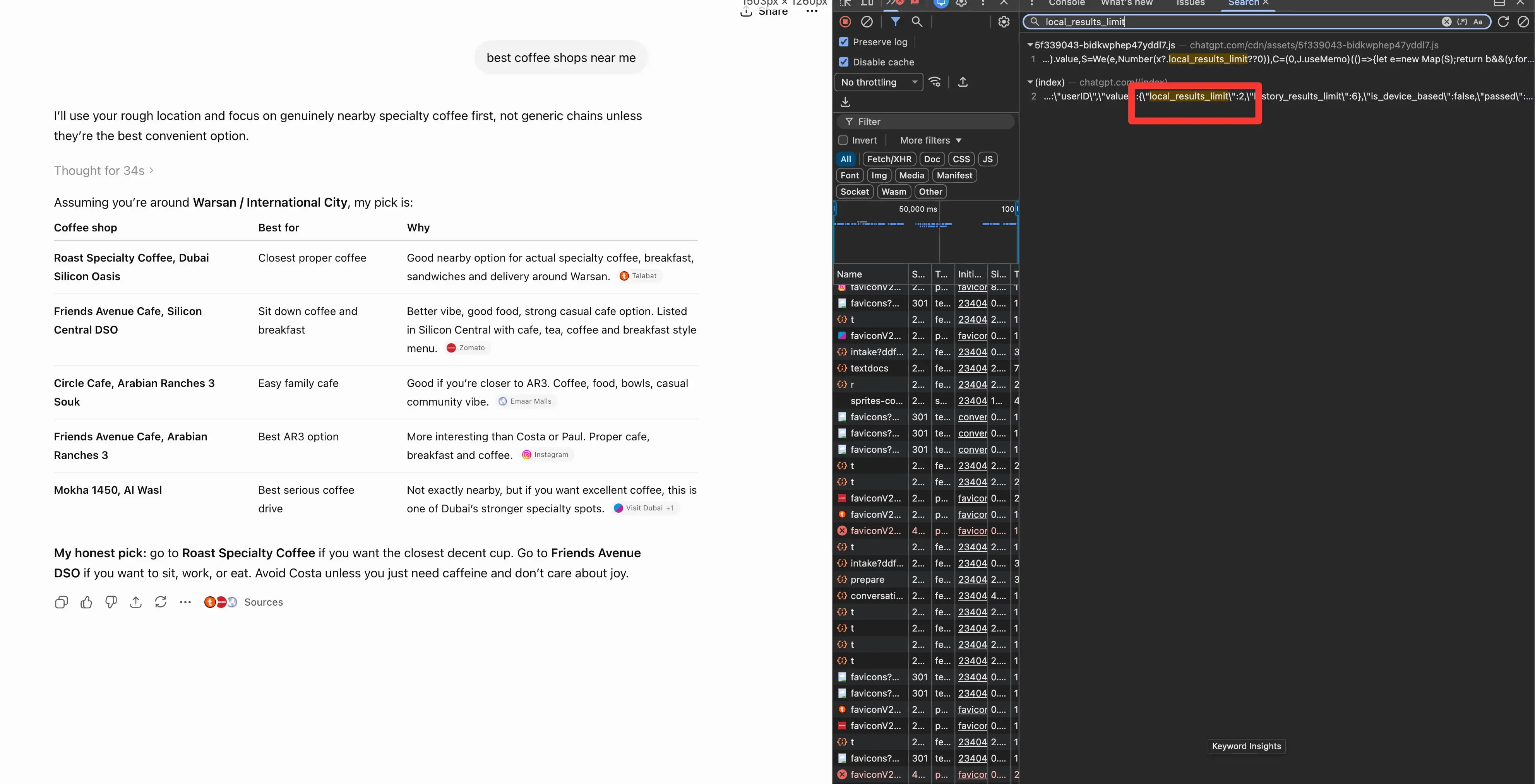
Ask for the finest espresso close to you, and ChatGPT returns two locations, not a prime 10. For native, you’re in the prime 2, otherwise you aren’t there.
One factor I genuinely can’t name but. My learn on buying comes from a single buying question, and it flatly contradicts what Mark noticed on his single question, so the buying combine is unsettled till somebody runs a correct batch.
And the wider caveat, stated plainly. The construction I’m positive of, as a result of I noticed it throughout roughly 1,240 data. The chances come from a small batch of economic queries, principally SaaS and tech, in order that they want a much bigger run throughout actual verticals before anybody banks on them.
That run is the subsequent piece.
Run It Your self
None of this wants particular entry or requires you to be related to the Matrix and turn out to be an operator, simply your personal browser.

Open ChatGPT, press Cmd+Choice+I for DevTools, open Community, tick Protect log, run a question, then press Cmd+Choice+F and search the responses for result_source.
That alone reveals you the pipeline behind every hyperlink.
For the relaxation, the fan-out and the citations and the reasoning, open the Console, kind permit pasting as soon as, and run this towards a dialog that searched the net.
const t = (await (await fetch('/api/auth/session')).json()).accessToken;
const c = await (await fetch('/backend-api/dialog/' + location.pathname.cut up('/c/')[1], {headers: {Authorization: 'Bearer ' + t}})).json();
const rows = [];
JSON.stringify(c, (ok, v) => {
if (v && v.result_source) {
const d = (v.attribution || v.url || '?').toString();
rows.push({supply: d.exchange('https://', '').exchange('www.', '').cut up('/')[0], pipeline: v.result_source});
}
return v;
});
console.desk(rows);It reads solely your personal session, so nothing leaves your machine. The output is a plain desk of every supply and the pipeline that fetched it.
supply pipeline
techradar.com labrador
whathifi.com labrador
soundguys.com shiny
rtings.com shiny
khaleejtimes.com oxylabs
streetinsider.com serpChange what the loop collects, and you may pull the searches, the citations, and the reasoning the similar means.
A Free Extension Now Captures Most Of This
If pasting scripts into your personal console isn’t your factor, there’s now a better route. Olivier de Segonzac already ran a free Chrome extension that pulls ChatGPT’s search and fan-out information.
He learn this analysis and prolonged it to seize three of the indicators I took aside above.
- The
turn_use_casebucket. The intent label ChatGPT information every flip below, so you’ll be able to spot when a question flips to buying, native, ortextual contentbefore it even solutions. - The reference-type combine. What number of of the reply’s citations had been merchandise versus search outcomes, information, or photos, parsed straight from the reference tokens.
- The
result_sourcepipeline. The scraper behind every cited consequence, charted per dialog, so the Vivid Information, Oxylabs, Labrador, and SERP cut up reveals up with out you studying a line of JSON.
It runs regionally on your personal session and exports straight to Excel. Seize it from the Chrome Web Store, and Olivier wrote up the update here.
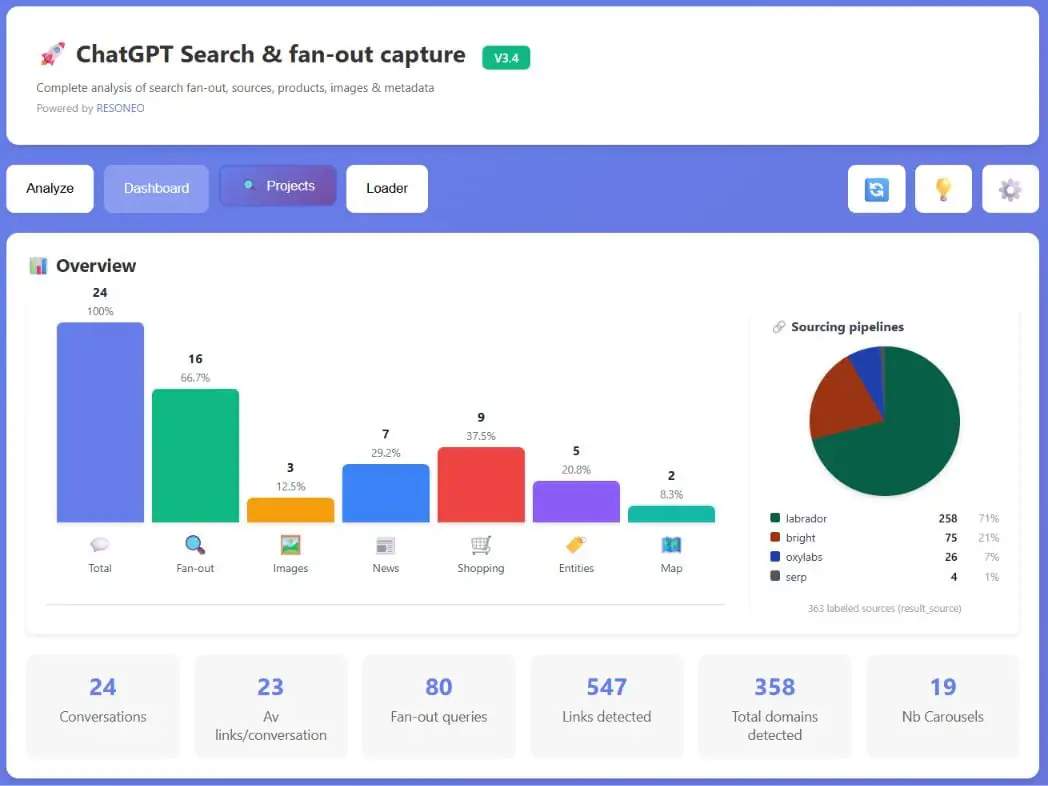
So, again to the query we opened with. Does the traditional recommendation maintain up? Largely. Reddit earns citations and topped my cited checklist. Listicles and evaluation websites make up most of the relaxation. Good content material nonetheless issues, however solely the half the mannequin can truly learn. The remaining it reads off another person’s web page.
Which is the actual lesson. ChatGPT isn’t a search engine, so cease optimizing for one.
It reads your personal web page for the information, if it may possibly parse them, and everybody else’s for the opinion, and solely when the query is price a search. Construct for that.
And deal with all of this, mine included, as a snapshot of a system that modifications by the week. The construction holds. The numbers transfer.
Whereas I used to be in the site visitors, I additionally discovered a pile of issues with nothing to do with sourcing: the bot wall that stops you scripting it, a hidden buying engine, and 573 dwell experiments operating on the account. These will probably be printed individually.
I’ve additionally accomplished comparable evaluation on Perplexity, Gemini, and so forth., so I’ll be sharing these quickly.
Extra Assets:
This publish was initially printed on Suganthan.
Featured Picture: Viktoriia_M/Shutterstock
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.