
There has by no means been a extra essential time in your profession to spend time studying and understanding. Not as a result of AI search differs drastically from conventional search. However as a result of everybody else thinks it does.
Each C-suite in the country is desperate to get this right. Resolution-makers want to really feel assured that you just and I are the proper folks to lead us into the new frontier.
We want to study the fundamentals of information retrieval. Even when your enterprise shouldn’t be doing something in another way.
Right here, that begins with understanding the fundamentals of mannequin coaching knowledge. What is it, how does it work and – crucially – how do I get in it.
TL;DR
- AI is the product of its coaching knowledge. The standard (and amount) the mannequin trains on is key to its success.
- The online-sourced AI knowledge commons is quickly turning into extra restricted. This will skew knowledge representativity, freshness, and scaling legal guidelines.
- The extra constant, correct model mentions you may have that seem in coaching knowledge, the less ambiguous you are.
- High quality website positioning, with higher product and conventional advertising, will enhance your look in the coaching and knowledge, and finally with real-time RAG/retrieval.
What Is Coaching Knowledge?
Coaching knowledge is the foundational dataset utilized in coaching LLMs to predict the most applicable subsequent phrase, sentence, and reply. The info will be labeled, the place fashions are taught the proper reply, or unlabeled, the place they’ve to determine it out for themselves.
With out high-quality coaching knowledge, fashions are utterly ineffective.
From semi-libelous tweets to movies of cats and nice artworks and literature that stand the check of time, nothing is off limits. Nothing. It’s not simply phrases both. Speech-to-text fashions want to be educated to reply to completely different speech patterns and accents. Feelings even.

How Does It Work?
The fashions don’t memorize, they compress. LLMs course of billions of knowledge factors, adjusting inner weights by a mechanism often known as backpropagation.
If the subsequent phrase predicted in a string of coaching examples is appropriate, it strikes on. If not, it will get the machine equal of Pavlovian conditioning.
Bopped on the head with a stick or a “good boy.”
The mannequin is then ready to vectorize. Making a map of associations by time period, phrase, and sentence.
- Changing textual content into numerical vectors, aka Bag of Phrases.
- Capturing semantic which means of phrases and sentences, preserving wider context and which means (phrase and sentence embeddings).
Guidelines and nuances are encoded as a set of semantic relationships; this is often known as parametric memory. “Data” baked immediately into the structure. The extra refined a mannequin’s information on a subject, the much less it has to use a type of grounding to verify its twaddle.
Value noting that fashions with a excessive parametric reminiscence are sooner at retrieving correct information (if obtainable), however have a static information base and actually neglect issues.
RAG and stay net search is an instance of a mannequin utilizing non-parametric reminiscence. Infinite scale, however slower. A lot better for information and when outcomes require grounding.
Crafting Higher High quality Algorithms
When it comes to the coaching knowledge, drafting higher high quality algorithms depends on three components:
- High quality.
- Amount.
- Removing of bias.
High quality of knowledge issues for apparent causes. If you happen to prepare a mannequin on poorly labeled, solely artificial knowledge, the mannequin efficiency can’t be anticipated to precisely mirror actual issues or complexities.
Amount of knowledge is an issue, too. Primarily as a result of these corporations have eaten all the pieces in sight and finished a runner on the invoice.
Leveraging artificial knowledge to resolve problems with scale isn’t essentially an issue. The times of accessing high-quality, free-to-air content material on the web for these guys are largely gone. For 2 foremost causes:
- Until you need diabolical racism, imply feedback, conspiracy theories, and plagiarized BS, I’m not certain the web is your man anymore.
- In the event that they respect firm’s robots.txt directives at the least. Eight in 10 of the world’s biggest news websites now block AI training bots. I don’t understand how efficient their CDN-level blocking is, however this makes high quality coaching knowledge more durable to come by.
Bias and variety (or lack of it) is an enormous drawback too. Folks have their very own inherent biases. Even the ones constructing these fashions.
Surprising I do know…
If fashions are fed knowledge unfairly weighted in the direction of sure traits or manufacturers, it will possibly reinforce societal points. It may well additional discrimination.
Keep in mind, LLMs are neither clever nor databases of details. They analyze patterns from ingested knowledge. Billions or trillions of numerical weights that decide the subsequent phrase (token) following one other in any given context.
How Is Coaching Knowledge Collected?
Like each good website positioning, it relies upon.
- If you happen to constructed an AI mannequin explicitly to establish footage of canines, you want footage of canines in each conceivable place. Each kind of canine. Each emotion the pooch exhibits. You want to create or procure a dataset of thousands and thousands, perhaps billions, of canine photos.
- Then it have to be cleaned. Consider it as structuring knowledge right into a constant format. In stated canine state of affairs, perhaps a feline pal nefariously added footage of cats dressed up as canines to mess you round. These have to be recognized.
- Then labeled (for supervised studying). Knowledge labeling (with some human annotation) ensures now we have a sentient being someplace in the loop. Hopefully, an professional to add related labels to a tiny portion knowledge, so {that a} mannequin can study. For instance, a dachshund sitting on a field trying melancholic.
- Pre-processing. Responding to points like cats masquerading as canines. Guaranteeing you reduce potential biases in the dataset like particular canine breeds being talked about way more steadily than others.
- Partitioned. A portion of the knowledge is stored again so the mannequin can’t memorise the outputs. This is the last validation stage. Sort of like a placebo.
This is, clearly, costly and time-consuming. It’s not possible to take up lots of of 1000’s of hours of experience from actual folks in fields that matter.
Consider this. You’ve simply damaged your arm, and also you’re ready in the ER for six hours. You lastly get seen, solely to be advised you had to wait as a result of all the docs have been processing photos for OpenAI’s new mannequin.
“Sure sir, I do know you’re in excruciating ache, however I’ve obtained a hell of a number of unhappy trying canines to label.”
Knowledge labeling is a time-consuming and tedious course of. To fight this, many companies rent massive groups of human knowledge annotators (aka people in the loop, you understand, precise consultants), assisted by automated weak labeling fashions. In supervised studying, they kind the preliminary labeling.
For perspective, one hour of video data can take humans up to 800 hours to annotate.
Micro Fashions
So, corporations construct micro-models. Fashions that don’t require as a lot coaching or knowledge to run. The people in the loop (I’m certain they’ve names) can begin coaching micro-models after annotating just a few examples.
The fashions study. They prepare themselves.
So over time, human enter decreases, and we’re solely wanted to validate the outputs. And to be certain that the fashions aren’t attempting to undress children, celebrities, and your coworkers on the internet.
However who cares about that in the face of “progress.”
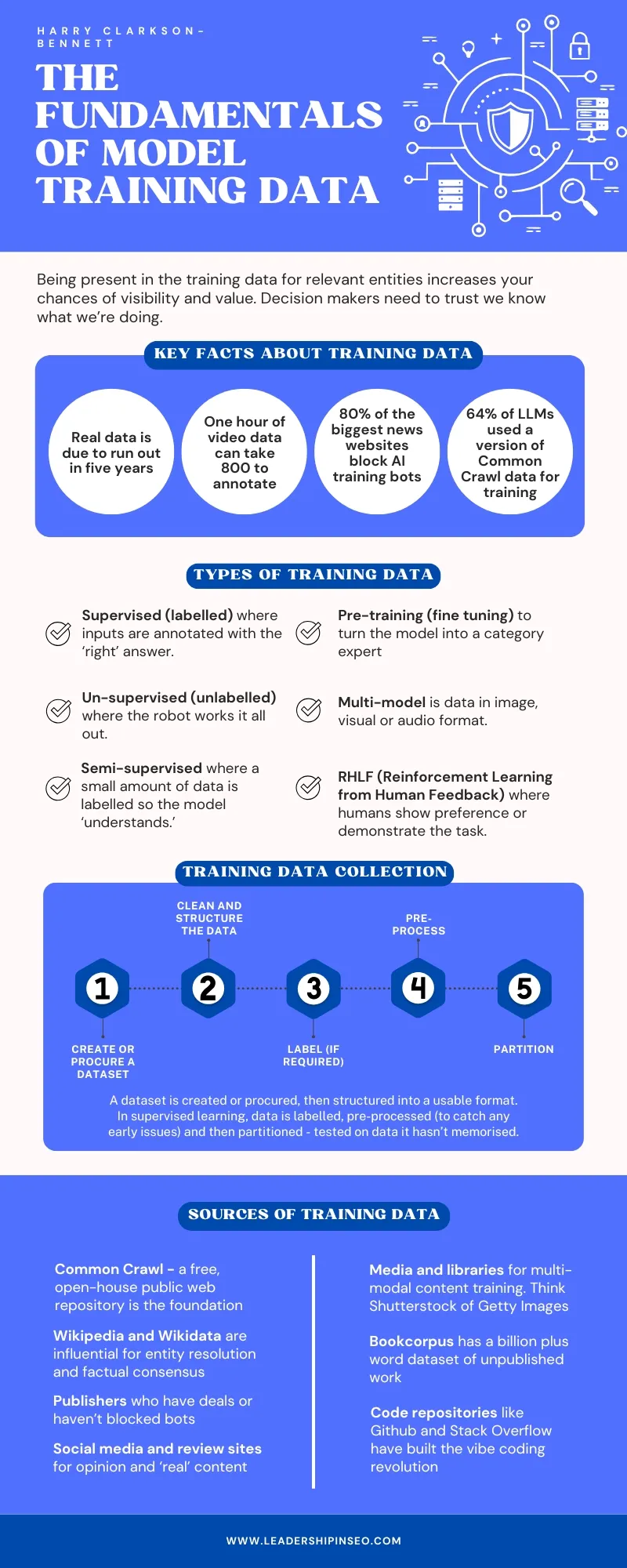
Varieties Of Coaching Knowledge
Coaching knowledge is often categorized by how a lot steering is supplied or required (supervision) and the function it performs in the mannequin’s lifecycle (perform).
Ideally a mannequin is largely educated on actual knowledge.
As soon as a mannequin is prepared, it may be educated and fine-tuned on artificial knowledge. However artificial knowledge alone is unlikely to create high-quality fashions.
- Supervised (or labeled): The place each enter is annotated with the “proper” reply.
- Unsupervised (or unlabeled): Work it out your self, robots, I’m off for a beer.
- Semi-supervised: the place a small quantity of the knowledge is correctly labeled and mannequin “understands” the guidelines. Extra, I’ll have a beer in the workplace.
- RLHF (Reinforcement Studying from Human Suggestions): people are proven two choices and requested to decide the “proper” one (choice knowledge). Or an individual demonstrates the job at hand for the mode to imitate (demonstration knowledge).
- Pre-training and fine-tuning knowledge: Large datasets permit for broad information acquisition, and fine-tuning is used to flip the mannequin right into a class professional.
- Multi-modal: Pictures, movies, textual content, and so on.
Then some what’s often known as edge case knowledge. Knowledge designed to “trick” the mannequin to make it extra sturdy.
In gentle of the let’s name it “burgeoning” marketplace for AI coaching knowledge, there are obvious issues of “fair use” surrounding it.
“We discover that 23% of supervised coaching datasets are printed underneath analysis or non-commercial licenses.”
So pay folks.
The Spectrum Of Supervision
In supervised studying, the AI algorithm is given labeled knowledge. These labels outline the outputs and are basic to the algorithm having the ability to enhance over time on its personal.
Let’s say you’re coaching a mannequin to establish colours. There are dozens of shades of every shade. A whole bunch even. So whereas this is a simple instance, it requires correct labeling. The issue with correct labeling is its time-consuming and probably pricey.
In unsupervised studying, the AI mannequin is given unlabeled knowledge. You chuck thousands and thousands of rows, photos, or movies at a machine, sit down for a espresso, after which kick it when it hasn’t labored out what to do.
It permits for extra exploratory “sample recognition.” Not studying.
Whereas this method has apparent drawbacks, it’s extremely helpful at figuring out patterns a human may miss. The mannequin can primarily outline its personal labels and pathway.
Fashions can and do prepare themselves, and they’re going to discover issues a human by no means may. They’ll additionally miss issues. It’s like a driverless automotive. Driverless automobiles could have fewer accidents than when a human is in the loop. But when they do, we find it far more unpalatable.

It’s the expertise that scares us. And rightly so.
Combatting Bias
Bias in coaching knowledge is very actual and probably very damaging. There are three phases:
- Origin bias.
- Improvement bias.
- Deployment bias.
Origin bias references the validity and equity of the dataset. Is the knowledge all-encompassing? Is there any apparent systemic, implicit, or affirmation bias current?
Improvement bias consists of the options or tenets of the knowledge the mannequin is being educated on. Does algorithmic bias happen due to the coaching knowledge?
Then now we have deployment bias. The place the analysis and processing of the knowledge leads to flawed outputs and automatic/suggestions loop bias.
You may actually see why we’d like a human in the loop. And why AI fashions coaching on artificial or inappropriately chosen knowledge can be a catastrophe.
In healthcare, knowledge assortment actions influenced by human bias can lead to the coaching of algorithms that replicate historic inequalities. Yikes.
Main to a reasonably bleak cycle of reinforcement.
The Most Regularly Used Coaching Knowledge Sources
Coaching knowledge sources are wide-ranging in each high quality and construction. You’ve obtained the open net, which is clearly a bit psychological. X, if you’d like to prepare one thing to be racist. Reddit, if you happen to’re on the lookout for the Incel Bot 5000.
Or extremely structured educational and literary repositories if you’d like to construct one thing, you understand, good … Clearly then you may have to pay one thing.
Widespread Crawl
Common Crawl is a public net repository, a free, open-source storehouse of historic and present net crawl knowledge obtainable to just about anybody on the web.
The complete Widespread Crawl Net Graph at present comprises round 607 million domain records across all datasets, with every month-to-month launch overlaying 94 to 163 million domains.
In the Mozilla Basis’s 2024 report, Training Data for the Price of a Sandwich, 64% of the 47 LLMs analysed used at the least one filtered model of Widespread Crawl knowledge.
If you happen to aren’t in the coaching knowledge, you’re not possible to be cited and referenced. The Common Crawl Index Server enables you to search any URL sample in opposition to their crawl archives and Metehan’s Web Graph helps you see how “centered you are.”
Wikipedia (And Wikidata)
The default English Wikipedia dataset contains 19.88 GB of complete articles that assist with language modeling duties. And Wikidata is an infinite, extremely complete information graph. Immensely structured knowledge.
Whereas representing solely a small share of the whole tokens, Wikipedia is maybe the most influential supply for entity decision and factual consensus. It is considered one of the most factually correct, up-to-date, and well-structured repositories of content material in existence.
A few of the largest guys have just signed deals with Wikipedia.
Publishers
OpenAI, Gemini, and so on., have multi-million greenback licensing offers with various publishers.
The checklist goes on, however just for a bit … and not not too long ago. I’ve heard issues have clammed shut. Which, given the state of their funds, could not be stunning.
Media & Libraries
This is primarily for multi-modal content material coaching. Shutterstock (photos/video), Getty Images have one with Perplexity, and Disney (a 2026 associate for the Sora video platform) supplies the visible grounding for multi-modal fashions.
As a part of this three-year licensing settlement with Disney, Sora will probably be ready to generate brief, user-prompted social movies based mostly on Disney characters.
As a part of the settlement, Disney will make a $1 billion fairness funding in OpenAI, and obtain warrants to buy extra fairness.
Books
BookCorpus turned scraped knowledge of 11,000 unpublished books right into a 985 million-word dataset.
We can not write books quick sufficient for fashions to regularly study on. It’s a part of the quickly to occur mannequin collapse.
Code Repositories
Coding has turn out to be considered one of the most influential and precious options of LLMs. Particular LLMs like Cursor or Claude Code are unimaginable. GitHub and Stack Overflow knowledge have constructed these fashions.
They’ve constructed the vibe-engineering revolution.
Public Net Knowledge
Various (however related) net knowledge leads to sooner convergence throughout coaching, which in flip reduces computational necessities. It’s dynamic. Ever-changing. However, sadly, a bit nuts and messy.
However, if you happen to want huge swathes of knowledge, perhaps in real-time, then public net knowledge is the method ahead. Ditto for actual opinions and evaluations of services and products. Public net knowledge, overview platforms, UGC, and social media websites are nice.
Why Fashions Aren’t Getting (A lot) Higher
Whereas there’s no scarcity of knowledge in the world, most of it is unlabeled and, thus, can’t really be utilized in supervised machine studying fashions. Each incorrect label has a unfavorable influence on a mannequin’s efficiency.
In accordance to most, we’re solely a few years away from running out of quality data. Inevitably, it will lead to a time when these genAI instruments begin consuming their very own rubbish.
This is a known problem that will cause model collapse.
- They are being blocked by corporations that do not need their knowledge used professional bono to prepare the fashions.
- Robots.txt protocols (a directive, not one thing immediately enforceable), CDN-level blocking, and phrases of service pages have been up to date to inform these guys to get misplaced.
- They devour knowledge faster than we are able to produce it.
Frankly, as extra publishers and web sites are pressured into paywalling (a wise enterprise determination), the high quality of those fashions solely will get worse.
So, How Do You Get In The Coaching Knowledge?
There are two apparent approaches I consider.
- To establish the seed knowledge units of fashions that matter and discover methods into them.
- To forgo the specifics and simply do nice website positioning and wider advertising. Make a tangible influence in your business.
I can see execs and cons to each. Discovering methods into particular fashions is most likely extremely pointless for many manufacturers. To me this smells extra like gray hat website positioning. Most manufacturers will probably be higher off simply performing some actually good advertising and getting shared, cited and you understand, talked about.
These fashions are not educated on immediately up-to-date knowledge. This is essential since you can not retroactively get into a particular mannequin’s coaching knowledge. You could have to plan forward.
If you happen to’re a person, you need to be:
- Creating and sharing content material.
- Going on podcasts.
- Attending business occasions.
- Sharing different folks’s content material.
- Doing webinars.
- Getting your self in entrance of related publishers, publications, and other people.
There are some fairly apparent sources of extremely structured knowledge that fashions have paid for in current instances. I do know, they’ve really paid for it. I don’t know what the guys at Reddit and Wikipedia had to do to get cash from these guys, and perhaps I don’t need to.
How Can I Inform What Datasets Fashions Use?
Everybody has turn out to be much more closed off with what they do and don’t use for coaching knowledge. I believe this is each legally and financially motivated. So, you’ll want to do some digging.
And there are some huge “open supply” datasets I believe all of them use:
- Widespread Crawl.
- Wikipedia.
- Wikidata.
- Coding repositories.
Fortuitously, most deals are public, and it’s protected to assume that fashions use knowledge from these platforms.
Google has a partnership with Reddit and entry to an insane quantity of transcripts from YouTube. They nearly actually have extra precious, well-structured knowledge at their fingertips than every other firm.
Grok educated nearly solely on real-time knowledge from X. Therefore why it acts like a pre-pubescent college shooter and undresses everybody.
Value noting that AI corporations use third occasion distributors. Factories the place knowledge is scraped, cleaned and structured to create supervised datasets. Scale AI is the knowledge engine that the large gamers use. Vivid Knowledge specialize in net knowledge assortment.
A Guidelines
OK, so we’re attempting to function in parametric reminiscence. To seem in the LLMs coaching knowledge so the mannequin acknowledges you and also you’re extra doubtless to be used for RAG/retrieval. Which means we’d like to:
- Handle the multi-bot ecosystem of coaching, indexing, and searching.
- Entity optimization. Effectively-structured, well-connected content material, constant NAPs, sameAs schema properties, and Data Graph presence. In Google and Wikidata.
- Make certain your content material is rendered on the server facet. Google has turn out to be very adept at rendering content material on the shopper facet. Bots like GPT-bot solely see the HTML response. JavaScript is nonetheless clunky.
- Effectively-structured, machine-readable content material in related codecs. Tables, lists, correctly structured semantic HTML.
- Get. Your self. Out. There. Share your stuff. Make noise.
- Be extremely, extremely clear on your web site about who you are. Reply the related questions. Personal your entities.
You could have to stability direct associations (what you say) with semantic associations (what others say about you). Make your model the apparent subsequent phrase.
Fashionable website positioning, with higher advertising.
Extra Assets:
Learn Management In website positioning, subscribe now.
Featured Picture: Collagery/Shutterstock
Disclaimer: This article is sourced from external platforms. OverBeta has not independently verified the information. Readers are advised to verify details before relying on them.













